Lenses SQL Engine¶
LSQL is a powerful SQL engine for Apache Kafka allowing people familiar with SQL to use Kafka at ease. It uses Apache Calcite industry standard SQL parser, and supports both batch and streaming queries. With the former, you can run ad-hoc SELECT queries to get an insight on the data already present in your Kafka topics. The latter gives you an intuitive syntax to aggregate, join and transform Kafka streams. You do not need to be a Kafka Streams expert to take full advantage of its capabilities.
The SQL engine supports Json and Avro payloads and comes with built-in support for nested fields selection, proper decimal handling for Avro, string functions, arithmetic support for integer/long/double/float/decimal and furthermore it allows you to address fields in both the key and value part of a Kafka message. For those not familiar with Apache Kafka, each message is made of a key and a value.
Why LSQL for Apache Kafka¶
The interest and usage of Apache Kafka are continuously growing. Many use cases involve moving data and applying transformations, aggregations, and look-ups on route to a target system such as a data store. The adoption, however, was hindered by users lack of experience with Java. Lenses SQL was the first SQL engine for Apache Kafka, that has enabled Data scientists, developers, business analysts to build robust solutions leveraging Kafka Streams and a few lines of SQL.
Traditional BI departments, that have been dealing with big and fast flowing data streams for many years, are well versed in running SQL on data pipelines. Often these teams are working on projects that involve migration of legacy systems to the cloud. They have the business knowledge and SQL technical skills. LSQL enables them to quickly start using Kafka and the wider streaming ecosystem around it.
Leveraging LSQL, you can focus on the business problems to be solved and you end up spending less time on frameworks, tools and infrastructure.
Topics and Messages¶
There is so much information available for Apache Kafka on the internet that going into a lot of detail will take the focus away from the subject. But, we need to build a bit of context to fully understand why and how LSQL will increase productivity.
Kafka is a streaming platform using messaging semantics. A Kafka cluster manages a collection of streams named
topics. A stream of data is divided horizontally into partitions. The partitions are replicated and distributed
through the Kafka cluster to achieve high availability.
A Kafka record (message) is composed of:
- key
- value
- metadata
- time-stamp
- topic
- partition
- offset
As a result, we allow the user to select any of them within LSQL. If you want to select a field from the key part the syntax is _key.id or even _key.*
to use the entire key value. A detail explanation is provided in the next chapter.
To extract maximum performance, Apache Kafka is not aware of the actual message content. All it knows is the message is made of two byte arrays. The advised approach is to use Apache Avro to handle the payload serialization step. By using Avro, the payload schema is enforced and furthermore, schema evolution is provided out of the box (there is a requirement for Schema management and Confluent Schema Registry tends to be the de-facto tool). However, we have seen a lot of software systems using Apache Kafka relying on JSON(JavaScript Object Notation) or Google Protobuf for the serialization.
Important
Apache Kafka does not know about the content of a message!
LSQL knows how to handle the following payload structures (also known as decoder types):
- BYTES
- JSON
- AVRO
- STRING/WSTRING
- INT/WINT
- LONG/WLONG
- PROTOBUF* (coming soon)
When using LSQL the user has to provide the decoders type. The SQL engine supports specific keywords for this: _ktype and _vtype.
The W… decoders are for Windowed keys. When aggregating based on a key and over the time window the resulting Kafka message key contains
the actual key (INT/LONG/STRING) plus the timestamp (epoch time).
Syntax¶
Lenses SQL uses MySQL syntax for dual purposes:
- read data from a topic [and partition/-s] while applying the required filters and functions on fields.
- build and run an Apache Kafka Streams application by using a simple SQL like syntax.
| Name | Description | Optional | Type |
|---|---|---|---|
| _key | Is used as a prefix and instructs LSQL to pick up the field from the Kafka message key part.
|
YES | |
| _ktype | Specifies what decoder to use for the
key component when reading from the given topic.See above for the decode types list.
|
NO | STRING |
| _vtype | Specifies what decoder to use for the
value component when reading from the given topic.See above for the decode types list.
|
NO | STRING |
| _partition | Specifies which partitions to read from. It can be
_partition=2 or _partition in (1,2,3).If used in a SELECT field list it returns the Kafka message partition number.
|
YES | INT |
| _offset | Specifies which offset to read from. It can be bounded by a specific range or a specific value.
If
_offset=123 one message is read. The user can restrict further by specifying lower/upperbound.``_offset >= 123 AND _offset < 999``. If used in a select gives back the Kafka offset.
|
YES | INT |
| _ts | Restricts the messages read based on their timestamp. Similar to
offset it can be boundedby a specific range or a specific value
_ts=1543366 or a range _ts > 123 AND _ts < 125.Please consult Apache Kafka documentation for timestamp information. If used in a SELECT
statement it returns the Kafka message timestamp.
|
YES | LONG |
Keywords
The SQL grammar has predefined keywords:
- timestamp
- partition
- topic
- date
These keywords can still be used as fields, but they must be escaped. It is recommended as with most SQL dialects to escape field and topic names. Below is an example of such query:
SELECT
`partition`
, `timestamp`
FROM `target_topic`
Important
Always escape the topic name via `. If you don’t and the topic contains non-alphanumeric characters the parsing will fail.
Browsing Topics¶
SELECT Syntax¶
Retrieves records from a Kafka topic and enables the selection of one or many columns from each message on the target topic. The full syntax of the SELECT statement is described below:
[ SET `max.bytes` = 1000000;]
[ SET `max.time` = 5000;]
[ SET `max.zero.polls` = 5;]
[ SET `{any.kafka.consumer.setting}`= `value`;]
SELECT select_expr [, select_expr ...]
FROM `Topic_Reference`
WHERE _ktype = KEY_TYPE
AND _vtype = VALUE_TYPE
[AND FILTERS]
[LIMIT N]
Aliasing is not allowed in this scenario. Since there is only one source topic, all the select_expr are automatically qualified to that topic.
Control execution¶
To control the resources involved and the time to execute the query, LSQL engine allows to set:
| Name | Description | Usage |
|---|---|---|
max.bytes |
The maximum amount of data to return
Default is 20MB
|
SET `max.bytes` = 20000000;will set a max of 20MB to be returned
|
max.time |
The maximum amount of time the query
is allowed to run in msec.
Default is 1 hour
|
SET `max.time` = 60000;sets a one minute query limit
|
max.zero.polls |
The maximum number of Kafka Consumer
poll operations returning zero records before
the query is completed.
Default is 8
|
SET `max.zero.polls` = 5;sets a maximum of 5 calls returning 0.
|
LIMIT N |
The maximum of records to return.
Default is 10000
|
SELECT *
FROM payments
WHERE _ktype = BYTES
AND _vtype = AVRO
LIMIT 100;
|
A real scenario, while browsing the data, is for the query to reach the end of the topic and none of the query boundaries to have been reached. In this scenario, the query will continue running until one of the limits is reached.
The max.zero.polls covers scenarios where all the data in the topic has been processed and none of the limits have been
reached. This setting will short-circuit, for example, a query running for 1 hour, if for 8 (default) consecutive Kafka polls,
there are no new records.
Sample scenario: Max time is set to 5 minutes and all the records have been processed in 30 seconds; then there is no reason to wait 4 minutes and 30 seconds before the query is completed.
Tune the underlying consumer¶
On very rare occasions, when browsing the data, there might be a requirement to tune the underlying consumer parameters.
LSQL allows setting the consumer properties. For example, to set the consumer fetch.max.wait.ms is as simple as:
SET `fetch.max.wait.ms`= `250`;
SELECT *
FROM `payments`
WHERE _ktype = JSON
AND _vtype = AVRO
LIMIT 10
Value Fields¶
The previous section has given a quick overview of what a Kafka message is composed of. To select fields within the value part of a message, the user has to just use the field name. For example, let’s assume the following message structure flows through your Kafka topic.
{
"user": "a user id",
"region" : "Europe",
"url" : "someurl",
"timestamp": 1503256766
}
To select the field named region from the message it is as simple as writing the query below:
SELECT region
FROM `web-traffic`
WHERE _ktype = BYTES
AND _vtype = AVRO
Notice the query specifies the format type for both key and value components of a Kafka message.
The result of such a query will be a new Avro record containing only one field: region.
If the format of the source topic is JSON the result would be a Json containing one field.
Important
When a JSON decoder type is used, it is expected the payload is the bytes representation of a Json object.
Not all the payloads stored in a Kafka message have a linear structure. Nested structures are quite a common scenario and LSQL has full support for selecting nested fields.
Consider the message structure below for the message value component:
{
"name": "Rick",
"address": {
"street": {
"name": "Rock St"
},
"street2": {
"name": "Sunset Boulevard"
},
"city": "MtV",
"state": "CA",
"zip": "94041",
"country": "USA"
}
}
We would want to flatten the structure. To do so, the following query can be used:
SELECT
name
, address.street.name AS address1
, address.street2.name AS address
, city
, state
, zip
, country
FROM `target_topic`
WHERE _ktype = BYTES
AND _vtype = AVRO
The result of such query statement will be a new Avro record containing seven fields: name, address1, address2, city, state, zip and country.
The same applies in case of a Json payload:
SELECT
name
, address.street.name AS address1
, address.street2.name AS address2
, city
, state
, zip
, country
FROM `target_topic`
WHERE _ktype = BYTES
AND _vtype = JSON
Key Fields¶
Many times, especially in IoT systems, device information is in the message key and it is not replicated in the message value part.
LSQL allows selecting the entire key (for primitive type: Int/Long/Double/String) or a specific field in case of Avro/Json structures.
To do that all it is required is to use the _key prefix.
Imagine a scenario where various metrics are obtained from an electrical device and the message key part structure looks like this:
{
"deviceId": 192211,
"model":"AX14c1"
}
To select the device id, the following query can be written:
SELECT
_key.deviceId
, meterValue
, ...
FROM `metrics`
WHERE _ktype = BYTES
AND _vtype = AVRO
Note
Prefix the field with _key if you want to select a field which is part of the key. Do not prefix with value/_value the fields you want to select from the Kafka message value part!.
Selecting Special Fields¶
Sometimes, a Kafka message payload will contain fields which are special keywords in the grammar (they might be function names or Apache Calcite specific grammar tokens) or they might start with a non-alphanumeric character. Selecting them as they are will lead to errors. For example:
SELECT
system.name
, @timestamp
,...
FROM `metrics`
WHERE _ktype = BYTES
AND _vtype = JSON
To get the above working the fields need to be escaped. LSQL is based on MySQL syntax, therefore the escaping character is `. The syntax correctly handling the two fields in:
SELECT
`system`.name
, `@timestamp`
,...
FROM `metrics`
WHERE _ktype = BYTES
AND _vtype = JSON
Functions¶
LSQL comes with support for string and arithmetic and logical functions. The table below contains the list of supported functions.
| Name | Description | Usage |
|---|---|---|
| ANONYMIZE | Obfuscates the data, in order to protect it. If the anonymized
value is not provided it will use
* for String and 0 for Numbers |
anonymize(expression [,Anonymized value]) |
| CAST |
|
cast(dt as int) |
| COALESCE | Returns the first non-null expression in the expression list.
You must specify two expressions
|
coalesce(value, prevValue) |
| CONCATENATE | Returns the string representation of concatenating each
expressionin the list. Null fields are left out
|
concatenate(weather.main, 'fixed', dt,temp.eve) |
| LEN | Returns the length of a string. LEN calculates length
using characters as defined by UTF-16
|
len(name) |
| POSITION | Return the position of the first occurrence of substring | position('math' in fieldA) |
| REPLACE | Returns string with every occurrence of
search_stringreplaced with
replacement_string |
replace(fieldA, 'math', 'mathematics') |
| SUBSTRING | Return a portion of the string, beginning at the given position | substring(field, 2) |
| TRIM | Removes leading and trailing spaces | trim(field) |
| LOWER | Returns the argument in lowercase | lower(name) |
| UPPER | Returns the argument in uppercase | upper(name) |
| ABS | Returns the absolute value of an
expressionit has to evaluate to a number type
|
abs(field1 + field2) |
| CEIL | Returns the absolute value of an
expressionit has to evaluate to a number type
|
ceil(field1) |
| FLOOR | Return the largest value not greater than the argument | floor(field1) |
| ‘/’ | Divides one number by another (an arithmetic operator)
Each expression has to evaluate to a number
|
a / b |
| ‘-‘ | Subtracts one number from another (an arithmetic operator)
Each expression has to evaluate to a number
|
a - b |
| ‘*’ | Multiplies one number from another (an arithmetic operator)
Each expression has to evaluate to a number
|
a * b |
| ‘+’ | Adds one number to another (an arithmetic operator)
Each expression has to evaluate to a number
|
a + b |
| ‘-‘ (negative) | Returns the negative of the value of a numeric expression
(a unary operator). The expression has to evaluate to a number
|
a * b |
| POW | Returns expression1 raised to the expression2 power.
Each expression has to evaluate to a number
|
pow(a, b) |
| SQRT | Returns the square root of expression.
The expression has to evaluate to a number
|
sqrt(a) |
| COUNT | Returns the number of records read
ONLY FOR STREAMING when grouping is involved |
SELECT count(*) |
| MAX | Returns maximum value of expression.
ONLY FOR STREAMING when grouping is involved |
max(field1) |
| MIN | Returns minimum value of expression.
ONLY FOR STREAMING when grouping is involved |
min(field1) |
| SUM | Returns the sum of expression for each record read.
ONLY FOR STREAMING when grouping is involved |
sum(field1) |
| IF | Evaluates the boolean result for condition. If true it will
return the value of expr1; otherwise, it evaluates and
returns the value of expr2
|
if(condition, expr1,expr2) |
| LPAD | Prepends the value of padExpr to the value of strExpr
until the total length is lengthExpr
|
LPAD(strExpr, lengthExpr, padExpr) |
| RPAD | Appends the value of padExpr to the value of strExpr
until the total length is lengthExpr
|
LPAD(strExpr, lengthExpr, padExpr) |
| EPOCH_TO_DATETIME | Converts an epoch into a datetime
yyyy-MM-dd'T'HH:mm:ss.SSSZstrExpr needs to be a LONG value containing the
milliseconds since 1 January 1970 00:00:00)
|
EPOCH_TO_DATETIME(strExpr) |
| EPOCH_TO_DATE | Converts an epoch into a date
yyyy-MM-ddThe strExpr needs to resolve to INT/LONG value. If the
value is an INT it is expected to be the day represented
as days since epoch
|
EPOCH_TO_DATE(strExpr) |
| DATETIME_TO_EPOCH | Converts a string representation of a datetime into epoch value.
For Avro records the new field will be of type Long with the
Timestamp logical type attached and the epoch value.
For Json records the epoch will be expressed as LONG.
The first parameter strExpr needs to be a STRING value.
The second parameter pattern must be a DateTime Format
|
DATETIME_TO_EPOCH(strExpr, pattern) |
| DATE_TO_EPOCH | Converts a string representation of a date into epoch value.
For Avro records, this will emit a field with a logical type of
Date. This means the output value is an INT and it represents
the days since Epoch. For Json records the resulted value is the
epoch expressed as LONG. The first parameter strExpr needs to
resolve to a STRING value. The second parameter pattern,
must be a Date Format
|
DATE_TO_EPOCH(strExpr, pattern) |
| CONVERT_TIME | Converts the string format of a date [and time]. The first
parameter strExpr needs be a STRING value. The second
parameter fromPattern is the incoming date[and time] format.
The last parameter represents the target date[and time] format.
|
CONVERT_TIME(strExpr, fromPattern, toPattern) |
CURDATE
CURRENT_DATE
|
Provides the current date value. For Json records the result
is a human readable date value represented as
yyyy-MM-dd.For Avro records the resulting field will be of type INT and
will have the logical type DATE attached
|
CURDATE()/CURRENT_DATE() |
CURRENT_DATETIME
NOW
CURTIME
|
Provides the current date and time. For Json records the
result is a human readable date and time value represented
as
yyyy-MM-dd'T'HH:mm:ss.SSSZ. For Avro records the resultingfield will be of type LONG and will have the
the logical type TIMESTAMP attached
|
NOW()/CURTIME()/CURRENT_DATETIME() |
Where Clause¶
Querying for data and filtering out records based on various criteria is a common scenario, hence LSQL has support for complex filter expression.
String Filter¶
If your field is of type string, any of the operators below can be used as part of the predicate describing which records to select and which ones to drop.
| Operation | Description |
|---|---|
| != | Checks inequality. When you want to filter all records with
field != 'ABC' |
| = | Checks for equality. When you want to filter all records with field == 'ABC' |
| < | Checks for less than. When you want to filter all records with field < 'ABC' |
| <= | Checks for less than or equal. When you want to filter all records with field <= 'ABC' |
| > | Checks for greater than. When you want to filter all records with field > 'ABC' |
| >= | Checks for greater than or equal. When you want to filter all records with field >= 'ABC' |
| like | Checks for prefix/contains/postfix. When you want to filter all records with the field containing the text:
field like '%ABC%'. To check for prefix field like 'ABC%'. To check for postfix field like '%ABC'.Comparison is case insensitive!.
|
Let’s assume you have an audit topic where you store changes made to data in your system and you want to see all the changes made by people whose name contains Alex.
To achieve that the following query can be used;
SELECT *
FROM audit
WHERE username LIKE '%Alex%'
AND _ktype = BYTES
AND _vtype = AVRO
Null Check¶
Some of the fields in the payload can be null (or missing in case of Json). Using the operations below a query can filter out any records where a field is null or not null:
| Operation | Description |
|---|---|
| is null | Checks the value is null. When you want to filter all records with field is null |
| is not null | Checks the value is not null. When you want to filter all records with field is not null |
SELECT *
FROM `visitorTracking`
WHERE _ktype = BYTES
AND _vtype = JSON
AND location.country IS NOT NULL
SELECT *
FROM `visitorTracking`
WHERE _ktype = BYTES
AND _vtype = JSON
AND location.country IS NULL
Filter on Numbers¶
LSQL allows you to apply filters for fields of number type: integer, short, byte, long, double, float, decimal.
The equality comparison for float and double happens within a precision range. Java uses a subset of IEEE 754 standard to represent floating point numbers.
Some floating point numbers, for example, 1/3, cannot be represented exactly using float and double in Java. As a result, equality needs to consider an epsilon.
LSQL uses 0.000001 for the value of the epsilon. If the two operands differ by less than the epsilon they are considered to be equal.
| Operation | Description |
|---|---|
| != | Checks for not equal. When you want to filter all records with field != 2 |
| = | Checks for equality. When you want to filter all records with field == 'ABC' |
| < | Checks for less than. When you want to filter all records with field < 123.4 |
| <= | Checks for less than or equal. When you want to filter all records with field <= 1000 |
| > | Checks for greater than. When you want to filter all record with field > -10 |
| >= | Checks for greater than or equal. When you want to filter all records with field >= 122.122315 |
SELECT *
FROM topic
WHERE _ktype = BYTES
AND _vtype = AVRO
AND location.latitude < -10
Filter on Partition¶
Sometimes a user will want to be able to look at one partition or a subset of partitions when applying a SELECT statement.
Then the query needs to use the _partition keyword to instruct which ones. For example:
SELECT
score
, userId
, sessionToken
FROM livescore
WHERE _ktype = BYTES
AND _vtype = JSON
AND _partition = 1
--or
SELECT
score
, userId
, sessionToken
FROM livescore
WHERE _ktype = BYTES
AND _vtype = JSON
AND _partition in (2,3)
Filter on Timestamp¶
LSQL allows for filtering by timestamp to enable selection of time windows you are interested in. For allowing such filtering LSQL uses the _ts filter.
Let’s say we want to see all the messages on a topic and partition where their timestamp is greater than 1501593142000L - epoch time.
SELECT
tradeId
, isin
, user
FROM `systemxtrades`
WHERE _ktype = BYTES
AND _vtype = AVRO
AND _partition = 1
AND _ts > 1501593142000
This is the same as if you were writing:
SELECT
tradeId
, isin
, user
FROM `systemxtrades`
WHERE _ktype = BYTES
AND _vtype = AVRO
AND _partition = 1
AND _ts > '2017-08-01 13:12:22'
Important
LSQL understands timestamp date format following this rule: yyyy-MM-dd HH:mm:ss[.SSS]
Boolean filter¶
There are scenarios where checking on a boolean field value is a requirement.
The SQL allows you to do so by simply specifying: is true or is false.
Let’s say we have a topic where credit cards metadata is stored and we want to only pick those ones which have been blocked.
Running the query below will allow you to achieve such functionality:
SELECT *
FROM credit_cards
WHERE _ktype=AVRO AND _vtype=AVRO AND blocked is true
IF Function¶
Sometimes it is required to pick a value based on a certain condition being met. The IF functions supports this scenario. Below is an example of using it:
SELECT IF((field1 + field2)/2 > 10 AND field3 IS NULL, field3 *10, field4+field6 * field8
FROM some_topic
WHERE _ktype=AVRO AND _vtype=AVRO AND blocked is true
Anonymize your data¶
At times you might not want the data published to a topic to contain sensitive information.
Therefore when a SQL Processor is created you might need to anonymize some of the data.
The grammar supports such a construct via the ANONYMIZE function.
SELECT anonymize(username), _key as card_number, lastTransactionTimestamp
FROM credit_cards
WHERE _ktype=AVRO AND _vtype=AVRO
Complex Filter¶
Applying a filter on a field sometimes is not enough. A user might want to apply algebra on a set of fields and filter based on the result, or maybe a user wants to look at a subset of a string field. LSQL allows you do do that.
SELECT *
FROM topicA
WHERE _ktype = BYTES
AND _vtype = AVRO
AND (a.d.e + b) /c > 100
LSQL allows the user to combine in the where clause fields from both key and value part. Here is an example of doing so:
SELECT *
FROM topicA
WHERE _ktype = AVRO
AND _vtype = AVRO
AND (_key.a.d.e + b) /_key.c < 100
SELECT *
FROM topicA
WHERE _ktype = BYTES
AND _vtype = AVRO
AND ((abs(fieldA) < 100 AND fieldB >= 2) OR (fieldC like '%wow'))
Track the usage¶
Using the configuration file, Lenses can be set to stores any LSQL query made for browsing. Alongside the query details, the information pushed to the topic also contains the user and the time it was executed.
Set the configuration entry lenses.topics.lsql.storage=_kafka_lenses_lsql_storage and it activates the functionality.
Then using the topic viewer screen the storage topic can be queried to see what are the most queries run.
Stream Processing¶
Apache Kafka ecosystem is enhanced by the Kafka Streams API which allows for data streams processing. The framework is available for the Java runtime, therefore you need to know you Java, Kotlin, Scala, etc. to make use of it. Not anymore. A Kafka Streams flow can be described by anyone with basic SQL skills.
Streaming Syntax¶
LSQL second usage is defining Kafka Streams flows through a SQL-like syntax. All the information learned so far is fully applicable to all the SELECT statements written for stream processing. The syntax, which might look complex initially, looks like this:
[ SET autocreate = true;]
[ SET partitions = 1;]
[ SET replication = 2;]
[ SET `decimal.scale`= 18;]
[ SET `decimal.precision`= 38;]
[ SET `ANY KAFKA STREAMS CONFIG. See Kafka documentation StreamsConfig, ConsumerConfig and ProducerConfig` = '';]
[ SET `topic.[ANY KAFKA Log CONFIG. See LogConfig]` = '';]
[ SET `rocksdb.[RocksDB specific configurations. See the section below on RocksDB]`= '';]
INSERT INTO _TARGET_TOPIC_
[WITH
_ID_NAME_ AS (SELECT [STREAM] ...FROM _TOPIC_ ...),
_ID_NAME_ AS (SELECT [STREAM] ...FROM _TOPIC_ ...)
]
SELECT select_expr [, select_expr ...]
FROM _ID_NAME_ INNER JOIN _OTHER_ID_NAME_ ON join_expr
[WHERE condition_expr]
[GROUP BY group_by_expr]
[HAVING having_expr]
If you are not familiar with Apache Kafka stream processing API please follow the documentation.
Important
Streaming SQL is not your typical RDBMS SQL. Core concepts around stream processing with Apache Kafka, the duality of Table/Stream, the implication of creating a Table versus a Stream instance, etc. need to be understood first.
Using LSQL for streaming allows you to do:
- Transformations
- Aggregation
- Join data
We will go through each one in detail but before we do so we need to expand on the syntax you have seen earlier.
Important
When using Avro payloads the schema needs to be present. LSQL engine does static validation against the existing schema. If the schema is missing an error will be returned.
Windowing¶
Windowing allows you to control how to group records which share the same key for stateful operations such as aggregations or join windows. Windows are tracked per record key. LSQL has support for the full spectrum of windowing functionality available in the Kafka Streams API.
Note
A record is discarded and will not be processed by the window if it arrives after the retention period has passed.
You can use the following types of windows in LSQL:
Hopping time windows. These are windows based on time intervals. They model fixed-sized, (possibly) overlapping windows. A hopping window is defined by two properties: the window’s size and its advance interval (aka “hop”). The advance interval specifies how much a window moves forward relative to the previous one. For example, you can configure a hopping window with a size 5 minutes and an advance interval of 1 minute. Since hopping windows can overlap a data record may belong to more than one such windows.
...
GROUP BY HOP(5,m,1,m)
...
Tumbling time windows. These are a special case of hopping time windows and, like the latter, are windows based on time intervals. They model fixed-size, non-overlapping, gap-less windows. A tumbling window is defined by a single property: the window’s size. A tumbling window is a hopping window whose window size is equal to its advance interval. Since tumbling windows never overlap, a data record will belong to one and only one window.
...
GROUP BY tumble(1,m)
...
Sliding windows. These express fixed-size window that slides continuously over the time axis. Here, two data records are said to be included in the same window if the difference of their timestamps is within the window size. Thus, sliding windows are not aligned to the epoch, but on the data record timestamps.
...
GROUP BY SLIDING(1,m)
...
Session windows. These are used to aggregate key-based events into sessions. Sessions represent a period of activity separated by a defined gap of inactivity. Any events processed that fall within the inactivity gap of any existing sessions are merged into the existing sessions. If the event falls outside of the session gap, then a new session will be created. Session windows are tracked independently across keys (e.g. windows of different keys typically have different start and end times) and their sizes vary (even windows for the same key typically have different sizes). As such session windows can’t be pre-computed and are instead derived from analyzing the timestamps of the data records.
...
GROUP BY SESSION(10,m, 5, m)
...
All the window functions allow the user to specify the time unit. Supported time windows are
| Keyword | Unit |
|---|---|
| MS | milliseconds |
| S | seconds |
| M | minutes |
| H | hours |
Table or Stream¶
When using Apache Kafka Streams API you can build a KStream or KTable from a topic. To distinguish between them, LSQL
uses the keyword STREAM. When the keyword is missing an instance of KTable is created. When the keyword is present an instance of KStream
is created.
Important
Use SELECT STREAM to create a KStream instance. Use SELECT to create a KTable instance.
Important
When creating a table the Kafka Messages must have a non-null key. Otherwise, the record is ignored.
KStream Settings¶
LSQL allows you to define a Kafka Stream flow with SQL-like syntax. From the target topic settings to the producer/consumer settings
LSQL allows the user to override the defaults. LSQL supports setting these configurations via a standard SQL pattern of
setting variables via SET. For example:
SET `auto.offset.reset` = 'smallest';
SET `processing.guarantee`= 'exactly_once'; //this is for Kafka 0.11+ enabling exactly once semantics
SET `commit.interval.ms` = 1000; //The frequency with which to save the position of the processor.
Any of the target topic specific configurations can also be specified here. Follow the Apache Kafka documentation here for a full list of topic specific configuration options. To set the configuration for the flow result topic you need to prefix the key with topic.. For example to set the cleanup policy to compact ` and to `flush.messages every 5 messages you need to configure LSQL as follows:
SET `topic.cleanup.policy`='compact';
SET `topic.flush.messages`= 5;
...
Apart from the topic, producer/consumer or Kafka stream configs, LSQL allows you to set the following:
| Setting | Description | Type | Example |
|---|---|---|---|
| autocreate | If the target topic does not exist it will create it. **If the
Kafka setup does not allow for auto topic creation the flow will fail!**
|
BOOLEAN | SET autocreate=true |
| partitions | The number of partitions to create for the target topic.
Applies only when autocreate is set to true. By default is false.
|
INTEGER | SET partitions=2 |
| replication | How many replicas to create for the target topic. Applies
only when autocreate is set to true. By default is false.
|
INTEGER | SET replication=3 |
| decimal.scale | When working with Avro records where decimal type is
involved it specifies the decimal scale.
|
INTEGER | SET `decimal.scale`=18 |
| decimal.precision | When working with Avro records where decimal type is
involved it specifies the decimal precision.
|
INTEGER | SET `decimal.precision`=38 |
Important
Each SET .. instruction needs to be followed by a semicolon:;.
Here is an example of setting the commit interval to 5 seconds and enabling exactly-once semantics (Apache Kafka 0.11+):
SET `commit.interval.ms` = 5000;
SET `processing.guarantee`= 'exactly_once';
INSERT INTO `hot_sensors`
SELECT
ip
, lat
, `long`
, (temp * 1.8 + 32) as metric
FROM `sensors`
WHERE _ktype = 'LONG'
AND _vtype = AVRO
AND temp > 30
Note
Configuring a stream flow via code requires the following configuration keys to be set: default.key.serde
and default.value.serde. LSQL takes care of this based on the values specified in the SQL so you don’t have to set them.
RocksDB Settings¶
Whenever the Kafka streams application requires state, it will rely on RocksDB. Configuring this key-value store breaks the pattern found in Kafka Streams API. To customize the settings one has to provide an implementation for org.apache.kafka.streams.state.RocksDBConfigSetter. LSQL covers most of the settings available, here is the entire list :
| Key | Type | Description | |
|---|---|---|---|
| rocksdb.table.block.cache.size | LONG | Set the amount of cache in bytes
that will be used by RocksDB.
If cacheSize is non-positive, then cache will not be used.
DEFAULT: 8M
|
|
| rocksdb.table.block.size | LONG | Approximate size of user data packed per block. Default: 4K | |
| rocksdb.table.block.cache.compressed.num.shard.bits | INT | TableFormatConfig.setBlockCacheCompressedNumShardBits | Controls the number of shards for the
block compressed cache
|
| rocksdb.table.block.cache.num.shard.bits | INT | Controls the number of shards for the block cache | |
| rocksdb.table.block.cache.compressed.size | LONG | Size of compressed block cache. If 0,
then block_cache_compressed is set to null
|
|
| rocksdb.table.block.restart.interval | INT | Set block restart interval | |
| rocksdb.table.block.cache.size.and.filter | BOOL | Indicating if we’d put index/filter blocks to the block cache.
If not specified, each ‘table reader’ object will pre-load index/filter
block during table initialization
|
|
| rocksdb.table.block.checksum.type | STRING | Sets the checksum type to be used with this table.
Available values: kNoChecksum, kCRC32c, kxxHash.
|
|
| rocksdb.table.block.hash.allow.collision | BOOL | Influence the behavior when kHashSearch is used.
if false, stores a precise prefix to block range mapping
if true, does not store prefix and allows prefix hash collision
(less memory consumption)
|
|
| rocksdb.table.block.index.type | STRING | Sets the index type to used with this table.
Available values: kBinarySearch, kHashSearch
|
|
| rocksdb.table.block.no.cache | BOOL | Disable block cache. If this is set to true,
then no block cache should be used. Default: false
|
|
| rocksdb.table.block.whole.key.filtering | BOOL | If true, place whole keys in the filter (not just prefixes).
This must generally be true for gets to be efficient.
Default: true
|
|
| rocksdb.table.block.pinl0.filter | BOOL | Indicating if we’d like to pin L0 index/filter blocks to the block cache.
If not specified, defaults to false.
|
|
| rocksdb.total.threads | INT | The max threads RocksDB should use | |
| rocksdb.write.buffer.size | LONG | Sets the number of bytes the database will build up in memory
(backed by an unsorted log on disk) before converting to a
sorted on-disk file
|
|
| rocksdb.table.block.size.deviation | INT | This is used to close a block before it reaches the configured
‘block_size’. If the percentage of free space in the current block is less
than this specified number and adding a new record to the block will
exceed the configured block size, then this block will be closed and the
new record will be written to the next block.
Default is 10.
|
|
| rocksdb.table.block.format.version | INT | We currently have three versions:
0 - This version is currently written out by all RocksDB’s versions by default.
Can be read by really old RocksDB’s. Doesn’t support changing
checksum (default is CRC32).
1 - Can be read by RocksDB’s versions since 3.0.
Supports non-default checksum, like xxHash. It is written by RocksDB when
BlockBasedTableOptions::checksum is something other than kCRC32c. (version
0 is silently upconverted)
2 - Can be read by RocksDB’s versions since 3.10.
Changes the way we encode compressed blocks with LZ4, BZip2, and Zlib
compression. If you don’t plan to run RocksDB before version 3.10,
you should probably use this.
This option only affects newly written tables. When reading existing
tables, the information about version is read from the footer.
|
|
| rocksdb.compaction.style | STRING | Available values: LEVEL, UNIVERSAL, FIFO | |
| rocksdb.max.write.buffer | INT | ||
| rocksdb.base.background.compaction | INT | ||
| rocksdb.background.compaction.max | INT | ||
| rocksdb.subcompaction.max | INT | ||
| rocksdb.background.flushes.max | INT | ||
| rocksdb.log.file.max | LONG | ||
| rocksdb.log.fle.roll.time | LONG | ||
| rocksdb.compaction.auto | BOOL | ||
| rocksdb.compaction.level.max | INT | ||
| rocksdb.files.opened.max | INT | ||
| rocksdb.wal.ttl | LONG | ||
| rocksdb.wal.size.limit | LONG | ||
| rocksdb.memtable.concurrent.write | BOOL | ||
| rocksdb.os.buffer | BOOL | ||
| rocksdb.data.sync | BOOL | ||
| rocksdb.fsync | BOOL | ||
| rocksdb.log.dir | STRING | ||
| rocksdb.wal.dir | STRING |
All the table configurations will initialize a BlockBasedTableConfig on which the call to set the values is made. This will be followed by a call to Options.setTableFormatConfig(tableConfig).
Transformations¶
This is the basic and most common use case. Transforming an incoming topic to morph the messages
using any of the capabilities provided by the SELECT statement. That includes:
- Selecting specific fields
- Applying supported functions to achieve a new field
- Filtering the records based on your criteria.
Let’s imagine we have a topic containing sensor specific data:
{
"device_id": 1,
"ip": "191.35.83.75",
"timestamp": 1447886791,
"lat": 22,
"long": 82,
"scale": "Celsius",
"temp": 22.0,
"device_name": "sensor-AbC-193X",
"humidity": 15,
"zipcode": 95498
}
And we want to select only that data where the temperature is over 30 degrees Celsius.
Furthermore, we want the temperature value to be expressed in Fahrenheit
and we only need ip, lat, long fields from the initial data. To do so we can write this LSQL statement:
INSERT INTO `hot_sensors`
SELECT
ip
, lat
, long
, (temp * 1.8 + 32) AS metric
FROM `sensors`
WHERE _ktype = 'LONG'
AND _vtype = AVRO
AND temp > 30
This is the simplest flow you could write and the query will end up producing records looking like this:
{
"ip": "191.35.83.75",
"lat": 22,
"long": 82,
"metric": 71.6
}
The SQL syntax allows you to access nested fields or a complex field. We can change slightly the structure above to do this. The new data looks like this:
{
"description":"Sensor embedded in exhaust pipes in the ceilings",
"ip":"204.116.105.67",
"id":5,
"temp":40,
"c02_level":1574,
"geo":{
"lat":35.93,
"long":-85.46
}
}
First, we write the SQL to address the nested fields:
INSERT INTO `new_sensors`
SELECT
ip
, geo.lat
, geo.long
, temp
FROM `sensors`
WHERE _ktype = 'LONG'
AND _vtype = AVRO
The result of applying this query will be Avro records with the following format:
{
"ip":"204.116.105.67",
"lat":35.93,
"long":-85.46,
"temp":40
}
If the user selects a complex field, the entire substructure is copied over. For example:
INSERT INTO `new_sensors`
SELECT
ip
, geo
, temp
FROM `sensors`
WHERE _ktype = 'LONG'
AND _vtype = AVRO
The new records will have this format:
{
"ip":"204.116.105.67",
"geo":{
"lat":35.93,
"long":-85.46
},
"temp":40
}
These examples are for records of type Avro, but the similar support is provided for Json payloads.
Aggregation¶
Typical streaming aggregation involves scenarios similar to these:
- Counting the number of visitors on your website per region
- Totalling amount of Foreign Exchange transactions for GBP-USD on a 15 minutes interval
- Totalling sales made on each of the company stores every day
- Retaining the minimum and maximum stock value on a 30 minutes interval
These are just a few examples - the list goes on. LSQL gives you a way of quickly express such aggregation over Kafka streams with either Json or Avro payloads.
Imagine a trading system needs to display the number of transactions made for each currency pair (GBPUSD is a currency exchange ticker). Such functionality can be easily achieved with a query like this:
INSERT INTO `total_transactions`
SELECT count(*) AS transaction_count
FROM `fx`
WHERE _ktype = BYTES
AND _vtype = AVRO
GROUP BY ticker
Remember this is a stateful stream so potentially, you could see the values for a ticker more than once. It depends on how many transactions flow through the Kafka topic. The result of this query could be the following:
| Key | Value |
|---|---|
| GBPUSD | 1 |
| CHFYEN | 1 |
| USDEUR | 1 |
| GBPUSD | 3 |
| USDEUR | 5 |
Suppose the user needs to look only at specific tickers. There are two approaches here where the filter is applied in the WHERE
clause (best for performance) or relying on HAVING clause. Both examples are covered by the queries below:
INSERT INTO `total_transactions`
SELECT count(*) AS transaction_count
FROM `fx`
WHERE _ktype = BYTES
AND _vtype = AVRO
AND ticker LIKE '%GBP%'
GROUP BY ticker
--OR
INSERT INTO `total_transactions`
SELECT count(*) as transaction_count
FROM `fx`
WHERE _ktype = BYTES
AND _vtype = AVRO
GROUP BY ticker
HAVING ticker in ('GBPUSD', 'EURDKK', 'SEKCHF')
Having clause allows the usage of any of the LSQL supported functions to achieve your filter requirements.
To illustrate that we will filter all the tickers for USD and the list: GBPUSD, EURDKK, SEKCHF
INSERT INTO `total_transactions`
SELECT count(*) as transaction_count
FROM `fx`
WHERE _ktype = BYTES
AND _vtype = AVRO
GROUP BY ticker
HAVING ticker IN ('GBPUSD', 'EURDKK', 'SEKCHF') OR ticker LIKE '%USD%'
There are scenarios where grouping by the record key part. Assume the fx topic contains the ticker in the key part. In that case, the queries become:
INSERT INTO `total_transactions`
SELECT count(*) AS transaction_count
FROM `fx`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
GROUP BY _key
-- OR adding a filter
INSERT INTO `total_transactions`
SELECT count(*) AS transaction_count
FROM `fx`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
AND _key.* LIKE '%GBP%'
GROUP BY _key
Important
Every time GROUP BY a field is involved, the resulting key on the target topic is STRING!
This is to allow joins on multiple fields.
In the version 1, LSQL does not support arithmetic on aggregation functions. By that we mean you can not do `SUM(fieldA)/count(*)`.
We are looking at solutions to address this in the upcoming version(-s). Meanwhile here is how you can do it for now:
SET `auto.offset.reset`='latest';
SET autocreate = true;
SET `commit.interval.ms` = 3000;
INSERT INTO sensor_data_avg
WITH
avgStream as
(
SELECT STREAM
COUNT(*) as total,
SUM(temperature) AS temperatureTotal,
SUM(humidity) AS humidityTotal,
MIN(temperature) AS minTemperature,
MAX(temperature) AS maxTemperature,
MIN(humidity) AS minHumidity,
MAX(humidity) AS maxHumidity
FROM `sensor_data`
WHERE _ktype='STRING' AND _vtype='JSON'
GROUP BY TUMBLE(2,s),_key
)
SELECT STREAM
temperatureTotal/total AS avgTemperature,
humidityTotal/total AS avgHumidity,
minTemperature,
maxTemperature,
minHumidity,
maxHumidity
FROM avgStream
Notice the last SELECT statement uses the output data from the first one in order to achieve the average calculation.
Important
Doing aggregate functions (SUM/COUNT/MIN/MAX) arithmetic is not supported!
Using Window¶
We have shown so far simple aggregation without involving windows. That might solve some of the requirements a user has. Aggregating over a window is a very common scenario for streaming. Window support was introduced earlier; please revisit the windowing section.
Keeping the trend of IoT scenarios, imagine there is a stream of metrics information from devices across the globe. The data structure looks like this:
{
"device_id": 2,
"device_type": "sensor-gauge",
"ip": "193.156.90.200",
"cca3": "NOR",
"cn": "Norway",
"temp": 18,
"signal": 26,
"battery_level": 8,
"timestamp": 1475600522
}
The following query allows you to count all the records received from each country on a tumbling window of 30 seconds. Such functionality can be described like this:
INSERT INTO norway_sensors_count
SELECT count(*) AS total
FROM sensors
WHERE _ktype = BYTES
AND _vtype = AVRO
GROUP BY tumble(30,s), cca3
The result would be records emitted on a 30 seconds interval and they would look similar to this:
| Key | Value |
|---|---|
| NOR | 10 |
| ROM | 2 |
| FRA | 126 |
| UK | 312 |
| US | 289 |
| NOR | 2 |
| FRA | 16 |
| UK | 352 |
| US | 219 |
Note
Remember the key value will be of type String.
So far we have done counting only but LSQL provides support for SUM, MIN or MAX as well.
Maybe your system processes customers orders and you want to keep computing every hour the total amount
of orders over the last 24 hours.
SELECT
product
, SUM(amount) AS amount
FROM Orders
WHERE _ktype = BYTES
AND _vtype = AVRO
GROUP BY HOP(1, H, 1,D), product
Joins¶
A join operation merges two streams based on the keys of their data records. The result is a new stream.
Note
LSQL supports joins on key, but also allows the user to join based on value/key part fields. This will end up with both sides having the key of the record remapped. The key is a result of string concatenation of the fields involved
Kafka Streams supports the following join operations:
KStream-to-KStreamJoins are always windowed joins, since otherwise the memory and state required to compute the join would grow infinitely in size. Here, a newly received record from one of the streams is joined with the other stream’s records within the specified window interval to produce one result for each matching pair. A new KStream instance representing the resulting stream of the join is returned from this operator.KTable-to-KTableJoins are join operations designed to be consistent with the ones in relational databases. Here, both changelog streams are materialized into local state stores first. When a new record is received from one of the streams, it is joined with the other stream’s materialized state stores to produce one result for each matching pair. A new KTable instance is produced representing the result stream of the join, which is also a changelog stream of the represented table.KStream-to-KTableJoins allow you to perform table lookups against a changelog stream (KTable) upon receiving a new record from another record stream (KStream). An example use case would be to enrich a stream of orders (KStream) with the order details(KTable). Only records received from the record stream will trigger the join and produce results, not vice versa. This results in a brand new KStream instance representing the result stream of the join.
Here is a table of joins supported by Apache Kafka Streams:
| Left Operand | Right Operand | Inner Join | Left Join | Outer Join |
|---|---|---|---|---|
| KStream | KStream | Yes | Yes | Yes |
| KTable | KTable | Yes | Yes | Yes |
| KStream | KTable | Yes | Yes | No |
LSQL supports these joins operators:
INNERLEFTOUTERRIGHT
Note
RIGHT JOIN will be expressed in terms of LEFT JOIN (The two operands are swapped)
Given the table above, here is a list of joins NOT possible by default in Kafka Streams API:
KTable RIGHT JOIN KStreamKTable OUTER JOIN KStreamKStream RIGHT JOIN KTable
LSQL ALLOWS the user to perform these operations, however, there are some costs associated with doing so.
But before more details are provided, we need to give an overview of the context at hand.
We said already a RIGHT JOIN is expressed as a LEFT JOIN and as a result, the above list becomes the following:
KStream LEFT JOIN KTableKTable OUTER JOIN KStreamKTable LEFT JOIN KStream
The challenge here is that a KTable can only be joined with another one. Furthermore, at the moment there is not a straightforward way to go from a KStream instance to a KTable one. The only solution is to use an intermediary topic and then build the KTable required off that topic. Of course, this will hurt performance since the data has to be written to a topic and read again to allow for the join to happen. The topology description for the flow will reflect such scenario. Given this information the above joins become:
KTABLE LEFT JOIN KTableKTable OUTER JOIN KTABLEKTABLE LEFT JOIN KTABLE
A KStream OUTER JOIN KTable, despite not having support in the Kafka Streams API, is translated to a
KStream OUTER JOIN KTable.
Important
LSQL transforms the flow as required to allow for the join type to happen. Fully understand the implications of making joins which require going through an intermediary topic.
Repartition¶
Apache Kafka Streams API does not allow joining two streams with a different partition count. This can easily be the case
in real systems. For example, with an order and order-detail topic, the partition count on latter will be smaller
since traffic is lower. To allow such a join LSQL makes sure it brings the two in line. As a result, it will have
to create an order-repartition (the name is just an illustration) matching the right operand version.
Such operation will have a direct impact on performance since the entire topic is copied over just to have the join. The topology viewer allows the user to see when such flow change appears.
Using WITH¶
As you have seen earlier, the full syntax for LSQL contains the following:
[WITH
_ID_NAME_ AS (SELECT [STREAM] ...FROM _TOPIC_ ...),
_ID_NAME_ AS (SELECT [STREAM] ...FROM _TOPIC_ ...)
]
This allows you to break down your query complexity. For example, let’s consider the scenario where you have a topic for static product details which you will want to join against the topic containing the orders. From the product details, you only need to store the product name. This is the SQL to use to achieve such behavior:
...
INSERT INTO ...
WITH
productTable AS
(
SELECT productName
FROM `product`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
)
SELECT ..
FROM ... JOIN productTable ON ...
...
Any names registered via WITH, in the example above product, can be referenced after its definition.
If your requirements are as such that you need to define multiple entries you can do so by separating all the
WITH via comma. For example:
WITH
productTable as
(
SELECT productName
FROM `product`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
),
userTable as
(
SELECT firstName, secondName
FROM `user`
WHERE _ktype = 'LONG'
AND _vtype = AVRO
)
The examples define tables (which translate into instances of a KTable) but you can specify a stream (which translates
to an instance of KStream) by simply adding STREAM after the SELECT:
WITH
productStream AS
(
SELECT STREAM productName
FROM `product`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
)
Important
If the right operand is not found in the list of entities defined by WITH a Stream instance will be created.
SELECT STREAM or SELECT within a join targets the left operand only.
Join on Key¶
When joins were introduced at the beginning of the chapter, it was stated that two records are matched when their keys are equal. Here is how you would join orders and order details for Avro records:
INSERT INTO orders_enhanced
SELECT STREAM
o.orderNumber
, o.status
, SUM(od.quantityOrdered * od.priceEach) total
FROM `order_details` AS od
INNER JOIN `orders` AS o
ON o._key = od._key
WHERE o._ktype = 'LONG'
AND o._vtype = AVRO
AND od._ktype = 'LONG'
AND od._vtype = AVRO
GROUP BY TUMBLE(2,s),o.orderNumber
Important
You can not join two topics when left operand value decoder differs from right operand value decoder. Joining values from different decoder types is not supported.
When joining streams the join needs to happen over a JoinWindow. The GROUP BY tumble(2,s) will be used as part of aggregation but also from it LSQL
will build an instance of JoinWindow instance to use when joining the streams but before apply the grouping.
The translation between Window and JoinWindow happens as described in the table below:
| Window Type | Join Window |
|---|---|
| tumble(duration) | JoinWindows.of(duration) |
| hop(duration,advance) | JoinWindows.of(duration).until(advance) |
| session(inactivity,duration) | JoinWindows.of(inactivity).until(advance) |
| slide(duration) | JoinWindows.of(duration) |
If your topics have Json payloads the above query should be:
INSERT INTO orders_enhanced
SELECT STREAM
o.orderNumber
, o.status
, SUM(od.quantityOrdered * od.priceEach) total
FROM `order_details` AS od
INNER JOIN `orders` AS o
ON o._key = od._key
WHERE o._ktype = 'LONG'
AND o._vtype = JSON
AND od._ktype = 'LONG'
AND od._vtype = JSON
GROUP BY TUMBLE(2,s),o.orderNumber
You can still join two streams without aggregating by simply doing the following:
INSERT INTO `orders_enhanced`
SELECT STREAM
od.orderNumber
, od.productCode
, od.quantityOrdered
, od.priceEach
, od.orderLineNumber
, p.productName
FROM `product` as p
INNER JOIN `order_details` AS od
ON p._key = od._key
WHERE p._ktype = BYTES
AND p._vtype = AVRO
AND od._ktype = BYTES
AND od._vtype = AVRO
GROUP BY TUMBLE(2,s)
Although GROUP BY is still used it is not actually applying grouping since no grouping fields were defined.
If your product topic key is not Avro, you can specify like in the example above, the _ktype='BYTES'.
This gives some performance benefit for not having to deserialize the LONG in the earlier example and serializing it back to the output topic.
Important
Do not use BYTES when the payload is Avro. The Avro content is
retained but the Schema Registry entry on the target will not be created.
All the functions supported by LSQL can be used in the select list. However unless grouping is involved the analytic ones: SUM, MIN, MAX,
COUNT are not allowed.
INSERT INTO `orders_enhanced`
SELECT STREAM
od.orderNumber
, od.productCode
, od.quantityOrdered
, od.priceEach
, od.orderLineNumber
, concat(od.productCode,'-',p.productName) AS productName
FROM `order_details` AS od
LEFT JOIN `product` as p
ON p.productCode = od.productCode
WHERE p._ktype = BYTES
AND p._vtype = AVRO
AND od._ktype = BYTES
AND od._vtype = AVRO
GROUP BY TUMBLE(4,s)
Join on Fields¶
It is not always the case that the topic key is actually the value to join on. Maybe it was an oversight in initial development. but LSQL has it covered as well. It allows you to chose a field from the Kafka message value part to use during the join.
INSERT INTO `order_details`
SELECT STREAM
o.orderNumber
, o.status
, o.flags
, od.productCode
FROM `order_details` AS od
INNER JOIN `orders` AS o
ON o.orderNumber = od.orderNumber
WHERE o._ktype = BYTES
AND o._vtype = AVRO
AND od._ktype = BYTES
AND od._vtype = AVRO
GROUP BY TUMBLE(2,s)
There is a trade-off here. Joining on a field like above means the stream needs to be remapped to allow for the new key.
All groupings will result in a String key. The reason is LSQL allows you to join on more than one field!
The key is a string concatenation of all the values involved.
Important
Joining on a value field(-s) will re-map the stream/table and the new key type will be String.
Re-mapping a table has it’s cost since it will have to move the data from the KTable to a new topic
and build a new instance of the table.
The standard way to handle joins with a table is to define the table via WITH. An optimal solution for
joining orders with products to get the product name attached to the order looks like this:
INSERT INTO `orders_enhanced`
WITH
productTable AS
(
SELECT productName
FROM `product`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
)
SELECT STREAM
od.orderNumber
, od.productCode
, od.quantityOrdered
, od.priceEach
, od.orderLineNumber
, p.productName
FROM `order_details` AS od
LEFT JOIN productTable AS p
ON p._key = od.productCode
WHERE od._ktype = BYTES
AND od._vtype = AVRO
First, a productTable is defined and it becomes the right operand for a LEFT JOIN. It is required for the
od.productCode to be of type String since the key on the table is String. Also, notice _ktype
is still required for order_details (od._ktype=’BYTES’). The resulting schema will
have the productName field as an optional string since the right side might not be present.
Examples¶
Data Browsing¶
Additional examples of filtering JSON or AVRO Kafka messages, based on pre-conditions on either the payload of the messages, or on message metadata:
-- Select all fields from a topic with AVRO messages, filtering messages with particular value payload
SELECT *
FROM topicA
WHERE f1 IS NULL
AND f2 = 3
AND f3 < 100
AND f4 >= 2
AND f5 <= 1
AND f6 > 12.4
AND f7 LIKE '%wow'
AND _ktype = AVRO
AND _vtype = AVRO
-- Select all fields from a topic with AVRO values, while filtering on nested Avro record fields
SELECT *
FROM topicA
WHERE p1.p2.f1 IS NULL
OR (p1.p2.f2 = 3 AND p1.p2.f3 < 100 AND (p1.p2.f4 LIKE 'wow%' OR p1.p2.f5 = 'wow' ))
AND _vtype = AVRO
-- Select all fields from a topic with JSON data, while filtering on nested Json record fields
SELECT *
FROM topicA
WHERE p1.p2.f1 is NOT NULL
OR (p1.p2.f2 <> 3 AND p1.p2.f3 < 100 AND (p1.p2.f4 like 'wow%' OR p1.p2.f5 = 'wow' ))
AND _vtype = JSON
-- Select some fields (cherry-pick) from a topic with JSON data where the message timestamp
SELECT field1.fieldA
, field2
, field3,
, _key.fieldM.fieldN AS N
FROM topicA
WHERE _vtype = JSON
AND _ts >= '2018-01-01 00:00:00'
-- Select fields from both the Key and the Value for messages in the first 15 minutes of 2018
SELECT field1.fieldA
, field2
, field3
, _key.fieldK AS keyField
FROM topicA
WHERE _vtype = JSON
AND _ts >= '2018-01-01 00:00:00'
AND _ts <= '2018-01-01 00:00:00'
Joins¶
-- LEFT JOIN messages from two topics, using a 4-second tumbling window and store results into target topic
INSERT INTO `toTopic`
SELECT STREAM
od.orderNumber
, od.productCode
, od.quantityOrdered
, od.priceEach
, od.orderLineNumber
, CONCAT(od.productCode,'-',p.productName) AS productName
FROM `OrdersDetailsTopic` AS od
LEFT JOIN `ProductTopic` AS p
ON p.productCode = od.productCode
WHERE p._ktype = BYTES
AND p._vtype = AVRO
AND od._ktype = BYTES
AND od._vtype = AVRO
GROUP BY TUMBLE(4,s)
-- RIGHT JOIN messages from two topics over a 10-minute tumbling window
INSERT INTO `toTopic`
WITH
product AS
(
SELECT productName
FROM `ProductTopic`
WHERE _ktype = 'STRING'
AND _vtype = AVRO
)
SELECT STREAM
od.orderNumber
, od.productCode
, od.quantityOrdered
, od.priceEach
, od.orderLineNumber
, p.productName
FROM product AS p
RIGHT JOIN `OrdersDetailsTopic` AS od
ON p._key = od.productCode
WHERE od._ktype = BYTES
AND od._vtype = AVRO
GROUP BY TUMBLE(10,m)
-- LEFT JOIN two topics with JSon data
INSERT INTO `toTopic`
SELECT STREAM
od.orderNumber
, od.productCode
, od.quantityOrdered
, od.priceEach
, od.orderLineNumber
, concat(od.productCode,'-',p.productName) as productName
FROM `OrdersDetailsTopic` AS od
LEFT JOIN `ProductTopic` AS p
ON p.productCode = od.productCode
WHERE p._ktype = BYTES
AND p._vtype = JSON
AND od._ktype = BYTES
AND od._vtype = JSON
GROUP BY TUMBLE(4,s)
-- Full LEFT JOIN of a stream with a table
SET `auto.offset.reset`='latest';
INSERT INTO `toTopic`
WITH
tableTelecom AS (
SELECT *
FROM `telecom_data`
WHERE _ktype = BYTES
AND _vtype = AVRO
)
SELECT STREAM
data.squareId
, grid.polygon
FROM `activity` AS data
LEFT JOIN tableTelecom AS grid
ON data._key = grid._key
WHERE data._ktype = BYTES
AND data._vtype = AVRO
Scaling Stream Processing¶
Lenses leverages Kafka Streams and currently provides three execution modes to run Lenses SQL processors. Processors is our term for a Kafka Streams application.
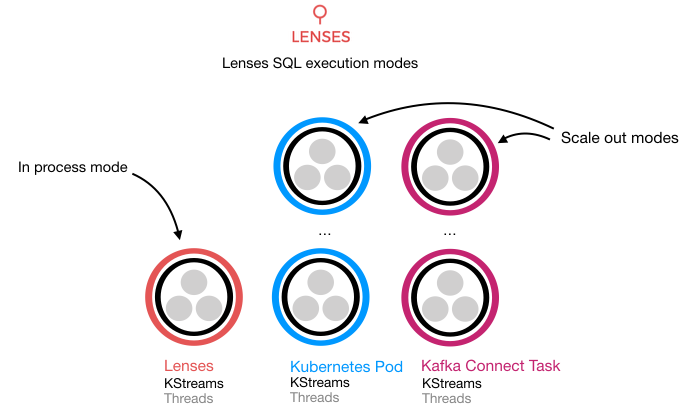
IN_PROC is the default execution mode and the processors are executed locally within Lenses. This can have
scalability issues and poses a risk to the running application, and can affect stability.
IN_PROC is recommended only for testing.
CONNECT is the execution mode that solves these limitations and provides availability guarantees and scalability.
Lenses can deploy your Lenses SQL processors in Kafka Connect. Kafka Connect provides a distributed, fault-tolerant and scalable
framework as part of the core Apache Kafka distribution. We advise allocating a Kafka Connect cluster for the purpose of running LSQL stream processing.
KUBERNETES is an execution mode that provides scalability by deploying Lenses SQL runners into Kubernetes clusters.
Lenses can deploy and monitor SQL runner deployments created through Lenses or existing tools such as Helm or kubectl.
Connect¶
Kafka Connect provides scalable, fault tolerant, distributed processing by forming a cluster of workers. The cluster provides endpoints to which Lenses will submit the processor configuration. From this point, Kafka Connect will persist configurations and distribute work to the cluster workers. Upon a restart Lenses will recover the status, configuration, and metrics of any Lenses SQL Connectors that are found in the configured clusters, this ensures that if Lenses is offline processing of data in your topologies continues. Lenses will also identify any connectors created outside of Lenses at runtime and start tracking them to provide you visibility.
To scale in or out the number of processor applications we can simply instruct Kafka Connect to decrease or increase the number of tasks across the cluster. The Lenses UI provides a simple way to deploy Lenses SQL processors and scale them, simply:
- Creating a new processor and selecting the cluster to deploy to
- Compose your SQL statement
- Set the parallelization .i.e many how tasks/application instances to run
- Give the processor a name
- Deploy
Lenses will check the validity of the SQL statement and if valid create the Connector instance and start to monitor its behavior.
Lenses supports the following Connector functionality:
CREATE- Register and create a new connectorPAUSE- Pause the connector and tasksSTART- Start a paused connectorDELETE- Remove a connector
Note
Updating an existing connector is not directly supported. The KStream app cannot be updated and the update is more than likely going to break the Schema compatibility of the target insert table but it can be scaled.
When Landoop’s FAST DATA CSD is used, the
Cloudera parcel lenses-sql-connect can install and provision the connector in a few seconds.
More information and step-by-step instructions on how to install the parcel can be found at FAST DATA docs
Kubernetes¶
Kubernetes, a container orchestration engine, provides the perfect platform to run
streaming microservices. It has the ability to ensure a configured number of application
instances or pods are running and to scale them up or down accordingly.
Via Helm charts, we provide a Dock image for the LSQL runner to deploy via CI/CD in a repeatable and audited manner.
Lenses can deploy SQL runners, recover the runners currently deployed and track and identify deployments created outside of Lenses.
The Lenses SQL Runner image accepts the same configuration options as environment variables as the Kafka Connect runner
with an additional sql.port to expose a rest endpoint.
Lenses deploys SQL runners as Kubernetes deployment resources. These deployments are labeled so Lenses can identify and track any changes via either Lenses or outside such as Helm or kubectl from a CI/CD pipeline.
The following labels are attached to deployments.
| Label | Value | Description | UserDefined | Resource |
|---|---|---|---|---|
| lenses | lenses-processor | Identifier of Lenses | No | Deployment |
| app | This is the name of
the processor, it must be unique.
If created via the Lenses API it will handle
this. It must also conform to
Kubernetes naming conventions,
[a-z0-9]([-a-z0-9]*[a-z0-9])?.
|
Yes | Deployment | |
| lenses-id | This is an auto-generated
tracking id. If created via Lenses
it will be assigned. If created outside of
Lenses it must not be set.
Lenses will assign a new id.
|
No | Deployment | |
| lenses-user | The username who created the deployment | Yes | Deployment | |
| containerPort | 8083 | The SQL runners expose a Restful
API so you can start, stop, get the status and metrics
of the underlying KStream. Additional
the internal RocksDb state store as exposed
to allow interactive queries
|
No | Pod |
| pipeline | A user-defined pipeline tag for monitoring | Yes | Pod |
Warning
Altering pod and deployment labels of existing SQL runner deployments may cause issues tracking the deployments.
The following rest endpoints are exposed by the containers. You can, for example, create a Kubernetes services with pod selectors to access them and access the state store for interactive queries.
# get health
curl pod_id:8083/health
# get metrics
curl pod_id:8083/metrics
# get the metadata, the internal state stored information for interactive queries
curl pod_id:8083/metadata
# get the metadata for the specified name, the internal state store for interactive queries
curl pod_id:8083/metadata/(name)
# get the stream information, sql, runners, consumer group id, username
curl pod_id:8083/stream
# stop the stream
curl -X POST pod_id:8083/stop
# start the stream
curl -X POST pod_id:8083/start
Deployment Recovery¶
Lenses can recover existing SQL deployments at startup that have been previously created by Lenses. Additionally, it can also track deployments created outside of Lenses. For example, you may be using Helm to control and manage deployments in your production environment out of a CI/CD pipeline.
Connect Data Stores¶
Kafka Connect is the tool to use for moving data in and out of Apache Kafka. We provide a handful of 25+ Connectors. Each source or sink have their own specific connection details. Working with our clients we realized the way Connect expects configuration is not allowing for easy connector management. To give you an example let’s take a JMS Sink. We want to push data from JMS topics to Kafka Topics. For that, we need a mapping between the JMS source and Kafka target. Let’s add on top a secure JMS connection and furthermore from each JMS payload we want a few fields. The way majority of connectors are written makes a nightmare to configure and manage such instances. Keep things simple and make Kafka accessible is our motto, therefore we provide a SQL like syntax to describe the above. Part of the Lenses SQL engine we call it KCQL (Kafka Connect Query Language).
Here is an example of a KCQL syntax for moving data from Kafka to JMS:
INSERT INTO /sensors
SELECT sensorId AS id,
minTemperature,
maxTemperature,
avgTemperature
FROM sensors_data
STOREAS JSON
WITHTYPE TOPIC
The SQL like syntax describes and drives the work the JMS sink will perform. It will pick the fields from the Kafka topic sensors_data and push it to a JMS topic /sensors. The resulting JMS messages payload will be JSON. Easy!
> “Keep things simple and make Kafka accessible is our motto.”
All our connectors support the following:
- Avro and JSON support
- Multiple Kafka topic to target mapping (for sinks)
- Multiple sources to target Kafka topic (for sources)
- Field selection, extraction, and filtering
- Auto creation & auto evolution for the target storage
- Error handling policies
KCQL Syntax¶
Here the full syntax our connectors share:
[INSERT|UPSERT]
INTO $TARGET
SELECT *|columns (i.e col1,col2 | col1 AS column1,col2, field1.field2.field3, field1.field2.field3 as f3)
FROM $TOPIC_NAME
[ IGNORE field1, field2,.. ]
[ AUTOCREATE ]
[ WITHSTRUCTURE ]
[ PK columns ]
[ WITHTARGET = target]
[ AUTOEVOLVE ]
[ BATCH = N ]
[ CAPITALIZE ]
[ INITIALIZE ]
[ PROJECTTO versionNumber]
[ PARTITIONBY cola[,colb] ]
[ DISTRIBUTEBY cola[,colb] ]
[ CLUSTERBY value1[,value2] INTO bucketsNumber BUCKETS ]
[ TIMESTAMP cola|sys_current ]
[ TIMESTAMPUNIT = timestampUnit]
[ WITHFORMAT TEXT|AVRO|JSON|BINARY|OBJECT|MAP ]
[ WITHUNWRAP ]
[ STOREAS $YOUR_TYPE([key=value, .....]) ]
[ WITHTAG (field1, tag2= constant, field2 as tag2) ]
[ INCREMENTALMODE = incrementalMode ]
[ WITHTYPE type ]
[ WITHDOCTYPE = docType ]
[ WITHINDEXSUFFIX = suffix ]
[ TTL = ttlType ]
[ WITHCONVERTER = converterClass ]
[ WITHJMSSELECTOR = jmsSelector ]
[ WITHKEY (field1, field2.field3) ]
[ KEYDELIM = value ]
Of course, the keywords, non-SQL specific, are not applicable at the same time. Each connector documentation details the keys it is using.
The SELECT mode is useful for target systems that do not support the concept of namespaces ( Key-Value stores such as HazelCast or Redis):
SELECT *|columns
FROM $TOPIC_NAME
[ IGNORE field1, field2,.. ]
[ PK columns ]
[ WITHSTRUCTURE ]
[ WITHFORMAT JSON|AVRO|BINARY ]
[ WITHUNWRAP ]
[ WITHGROUP theConsumerGroup]
[ WITHOFFSET (offset1)(offset2) ]
[ WITHPARTITION (partition),[(partition, offset) ]
[ SAMPLE $RECORDS_NUMBER EVERY $SLIDE_WINDOW ]
[ LIMIT limitValue ]
[ STOREAS $YOUR_TYPE([key=value, .....]) ]
[ WITHTAG (field1, tag2= constant, field2 as tag2) ]
[ INCREMENTALMODE = incrementalMode ]
[ WITHDOCTYPE = docType ]
[ WITHINDEXSUFFIX = suffix ]
[ WITHCONVERTER = converterClass ]
Here is a Redis Connector example:
"connect.redis.sink.kcql": "INSERT INTO sensorTimeseries SELECT sensorID, temperature, humidity FROM sensorsTopic STOREAS SortedSet (score=ts)",
The above KCQL instructs the Redis Kafka Sink Connector to select the three fields and store the time-series data into a Sorted Set, using the incoming field ts for scoring each message.