Lenses SQL¶
The Lenses SQL engine provides users with an enterprise-grade, expressive, powerful and declarative Structured Query Language with industry standard ANSI joins and aggregates for querying, transforming and manipulating data at rest and data in motion over Apache Kafka. To support the distinction for data at rest and data in motion, the engine is split into three components:
- Table based engine for your table (or bound, or point-in-time) queries.
- Data at rest and table are synonyms in this case. Just like your MySQL or Oracle table, a table in Lenses is, in most cases, changing over time. At the time of the query being executed the table holds a well-defined set of data. Each query made can be set to observe the data at a specific point in time. Therefore you can view the table as a resting place for your data.
- Streaming based engine for your continuous queries.
- Data in motion is synonym with streams in this scenario. Unlike a table, a stream observes the continuous evolution of your data with time.
- Kafka Connect based engine.
- Kafka Connect is the framework allowing for a distributed, scalable and fault-tolerant approach for moving data in and out of Apache Kafka. This mode is used to configure the connectors. Via a friendly SQL-like syntax the user can instruct the Kafka Connect Source/Sink what to do.
With the Table-based engine, you can quickly investigate your data, try out your joins that can be easily taken to a continuous query afterwards. There are many reasons why you would investigate your data; they span from looking for data anomalies to looking at a given record to checking a specific column (or field - the two notions are interchangeable) value for a given record.
The Streaming engine allows you to build reliable, scalable and fault tolerant low latency (or real-time if you prefer the term) data pipelines. This permits you to get valuable insights into your data as soon as it is received. You can enrich your transactions records in real-time with static information related to the customer, or you can see how many users are active on your e-commerce site on a minute by minute interval, or aggregate billions of thermostat readings to persist them for further analysis. And the list goes on.
Querying your data with SQL in table mode is as simple as executing the following query:
SELECT *
FROM payments
WHERE card_type='VISA'
AND amount > 10000
LIMIT 10
The engine components are supported by a large ecosystem of integration points like a JDBC driver, Python and Go clients, rest endpoints and command line interfaces.
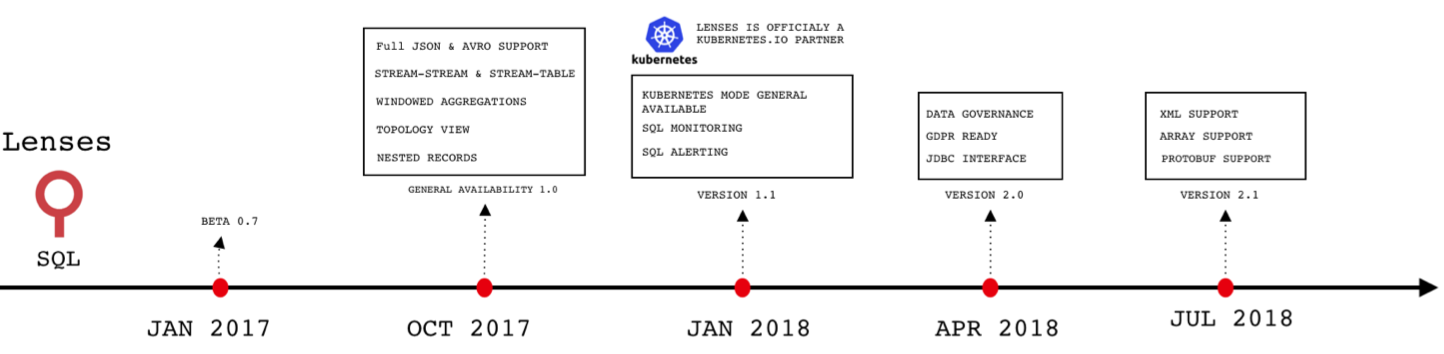
Impressive intellisense
Every aspect of Lenses is specifically designed to maximize user productivity. Using an intuitive design, the user interface aims to make writing Lenses SQL not only productive but also an enjoyable experience. The coding assistance offered by Lenses and its SQL engine helps the user stay productive when writing the desired tabled/streaming queries. Through its context-aware SQL parser, Lenses delivers fast and unobtrusive intelligence experience by giving instant and clever code completion no matter the current position in the SQL code. This goes beyond listing and filtering the available tables, as the user gets a fluid experience for selecting fields and functions all based on the current cursor position and the query written so far.
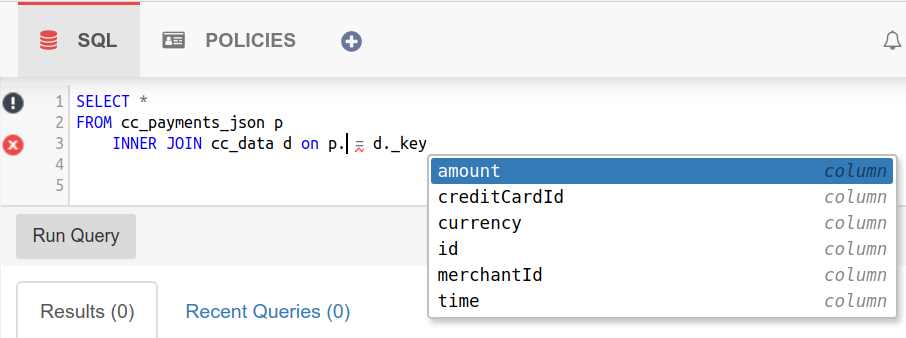
A SQL engine for any data format and any structure
A Kafka record is constructed of a key-value pair and metadata (offset, topic, timestamp, headers). When stored in a topic (or table - the terms are used here interchangeably) it can take various formats: AVRO, JSON, Protobuf or custom format.
The SQL engine has been written to handle out of the box AVRO, JSON, XML, CSV, STRING, INT, LONG and via extensions Google’s Protobuf or any other custom format one may use.
Irrespective of the data storage format, a user can select nested fields and arrays element, all using an ANSI SQL syntax. The query below has the same outcome regardless of the storage format (AVRO, JSON, XML, Google’s Protobuf or any other one):
SELECT speed
, longitude AS long
, latitude AS lat
, current_timestamp AS ts
FROM car_IoT
WHERE speed > 0
A rich set of functions are provided out of the box in order to support string, date and number manipulation. With the addition of User Defined Function, a user can provide their own functions to enrich the capabilities of Lenses SQL.
Auto-discovery of topics record format
Lenses platform does its best to understand the table storage format and regardless of the actual format, it keeps a table schema. It can work out if a topic contains AVRO, JSON, XML, INT or Binary data. However, distinguishing between String, Bytes, Int, Long is not possible without incurring a risk of falsely setting the payload. For the tables using these formats, or Google’s Protobuf or any custom format, user input is required. Lenses user interface makes it easy to set the formats, which is an operation that is required only once. When the tables are empty (i.e. there are no records present) Lenses does not have enough context to determine the payload type, hence it is required for the user to set both key and value payload.
Monitoring is built in
It is important to be able to monitor any executing SQL (be it Table-based or Streaming-based) in order for your team to have leverage in ensuring they meet their SLAs.
SQL streaming is a first class citizen; it receives special treatment and gets out of the box real-time performance metrics as well as its own topology graph (to see how it manipulates the data). Additionally, each SQL continuous query will show up in the Lenses powerful data pipeline topology graph.
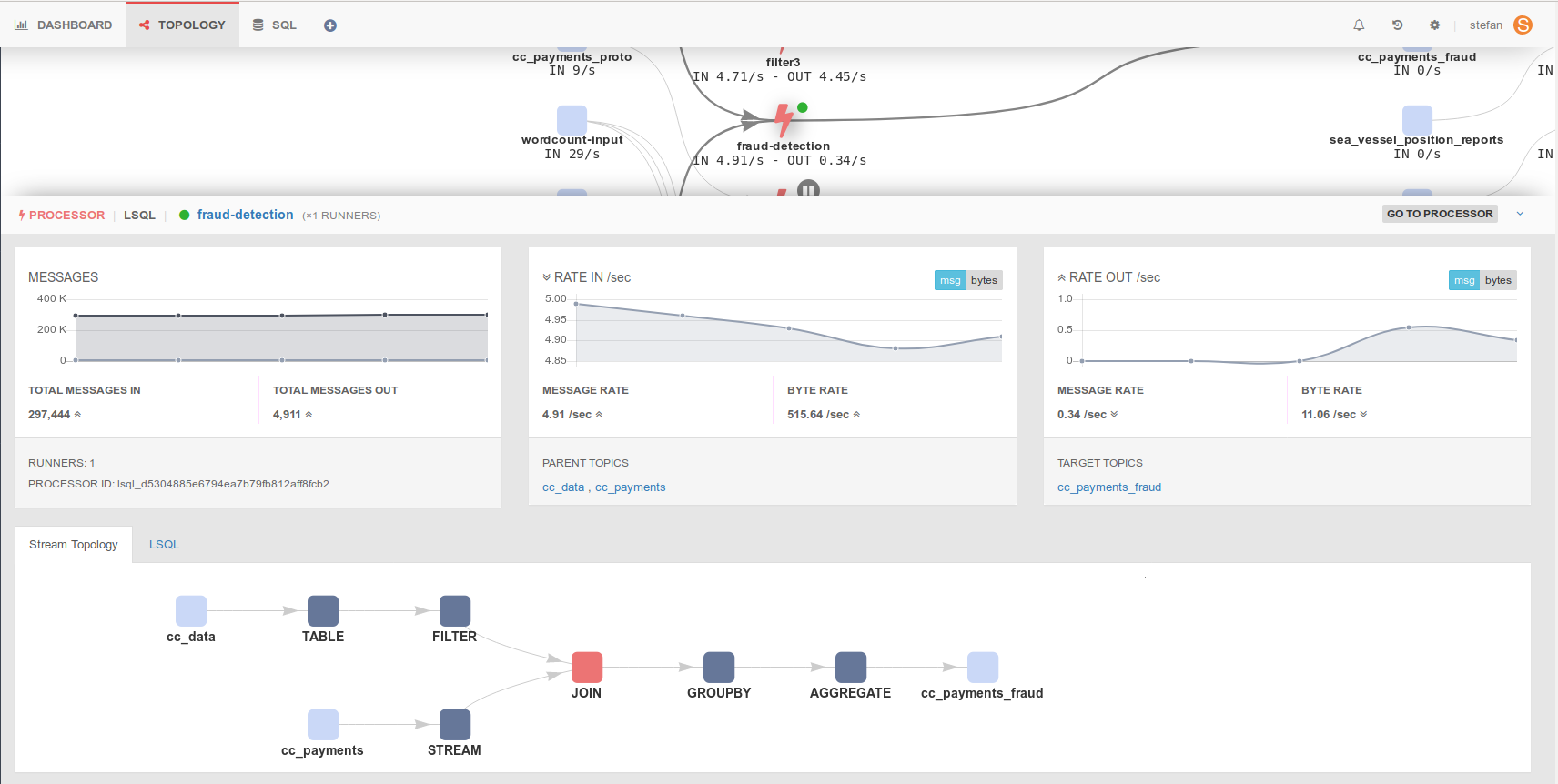
What you get with Lenses SQL
No Application Code
Lenses enables real-time data processing using SQL. The execution engine handles all the complexity of running real-time computation on data streams while providing live metrics for your queries.
Data enrichment
You can enrich your data in motion to enhance or refine it in order to make it correct and insightful to work with.
Streaming Ingestion with SQL capabilities
Once you have analyzed, enriched, or otherwise modified data, you will often want to write it out into a storage system. You “sink” the data. As part of Lenses SQL, we enhance the Kafka Connectors configuration with an idiomatic SQL syntax to instruct the target systems with special options, expressed by friendly SQL code.
Streaming Analytics
Joins, filters and aggregates, allow real-time streaming analytics to be performed. You can use it to build:
- Anomaly and threat detection
- Recommendations
- Predictive analytics
- Sentiment analysis
Machine Learning
By continuously filtering and transforming the data, you can ensure it is ready for scoring. Thus, you can:
- Continuously train models with real-time data
- Integrate with tools data scientists love ie. Jupyter notebooks
- Visualize data and topologies
Data Wrangling
Data Scientists spend most of their time cleaning and preparing their data before looking for insights. Lenses SQL makes it easy to spin up continuously running queries, over a massive amount of data to easily transform into a format that is easy to work with.
- Perform pre-analysis to correct, filter, route, clean and enhance messages in real time
- Build streaming SQL queries (sums, averages, aggregates, anonymize functions, etc.)
- Preview live data as it flows through so that you can see filters and transformations continuously throughout the pipeline
- Python native library, Jupyter integration
Contents
- Why SQL for Streaming
- Tables
- Table-based engine
- Learn in 10 minutes
- First query
- Record metadata
- Performing simple arithmetic
- Using functions
- Manipulating text columns
- Filtering with WHERE
- Missing values
- Multiple WHERE conditions
- Limit the output
- Read a table partition only
- Count the records
- Use SUM to aggregate your amounts
- Group data with GROUP BY
- Nested queries
- Filtering grouped data with HAVING
- Joins
- Managing Tables
- Managing Views and Synonyms
- Inserting and Deleting Data
- Querying a Table or View
- Supported Functions
- Date Math
- User Defined Functions
- User Defined Aggregate Functions
- Tuning
- How To
- Select a nested field
- Select an array field
- Limit the number of records read
- Limit the number of records based on data size
- Set a time limit for a query
- Filter on table partition
- Filter on text
- Date math
- Search for a record on a specific offset
- Filter on true/false
- Query for a null value
- Query for array size
- Filter on numbers
- Filter on Avro fields with a union of many types
- The IF Function
- Insert complex key
- Learn in 10 minutes
- Streaming-based engine
- Connect based engine
- Storage Formats