4.0
Concepts
LSQL Streaming mode is processing data seen as an independent sequence of infinite events. This is what Stream Processing means.
An Event in this context is a datum of information; the smallest element of information that the underlying system uses to communicate. In Kafka’s case, this is a Kafka record/message.
Two parts of the Kafka record are relevant:
- Key
- Value
These are referred as facets by the engine.
These two components can hold any type of data and Kafka itself is agnostic on the actual Storage Format for either of these two fields. More information about Storage Formats .
LSQL Streaming interprets records as (key, value) pairs, and it exposes ways to manipulate these pairs in several ways.
See Projections , Aggregations and Joins to know more about what the role of the Key and the Value is in the context of these features.
Expressions in Lenses SQL
An expression is any part of an LSQL query that can be evaluated to a concrete value (not to be confused as a record value).
In a query like the following:
INSERT INTO target-topic
SELECT STREAM
CONCAT('a', 'b') AS result1
, (1 + field1) AS result2
, field2 AS result3
, CASE
WHEN field3 = 'Robert' THEN 'It's bobby'
WHEN field3 = 'William' THEN 'It's willy'
ELSE 'Unknown'
END AS who_is_it
FROM input-topic
WHERE LENGTH(field2) > 5;
CONCAT('a', 'b'), (1 + field1) and field2 are all expressions which values will be projected onto the output topic, whereas LENGTH(field2) > 5 is an expression which value will be used to
filter out input records.
Below is the complete list of expressions that LSQL supports.
Literal
A literal is an expression that represents a concrete value of a given type. This means that there is no resolution needed for evaluating a literal and its value is simply what is specified in the query.
In the above example query 'a', 'b', 1 and 5 are literals, respectively
two strings and two integers.
Selection
A selection is an explicit reference to a field within a structured section (see Storage Formats ) of an input record. Additionally, the structure needs to have a valid schema registered in Lenses (see Prerequisites ).
The referenced field can be in the Key or in the Value section (the facet) of a record.
The syntax for a selection is as follows:
[<named_source>.][<facet>.]<field_name>
Where the optional <named_source> could be for example the topic name where the
record is read from, and _key or _value to specify in what section of the input record the field is read from.
In the above example query, field1, field2 and field3 are selections, and
could equally be written in their fully qualified form input-topic._value.field1,
input-topic._value.field2 and input-topic._value.field3.
Function
A function is a predefined named operation that takes a number of input arguments and is evaluated into a result. Functions usually accept the result of other expressions as input arguments, so functions can be nested.
LSQL Streaming supports out-of-the-box a great number of different functions , and this set can be further expanded when User Defined Functions and User Defined Aggregated Functions ) are used.
In the above example query CONCAT('a', 'b') and LENGTH(field2) are functions.
Binary Expression
A binary expression is an expression that is composed of a left-hand side and a right-hand side sub-expressions and an operator that describes how the results of the sub-expressions are to be combined into a single result.
Currently, supported operators are:
- Logical operators:
AND,OR - Arithmetic operators:
+,-,*,/,%(mod) - Ordering operators:
>,>=,<,<= - Equality operators:
=,!= - String operators:
LIKE,NOT LIKE - Inclusion operator:
IN
A binary expression is the main way to compose expressions into more complex ones.
In the above example query 1 + field1 and LENGTH(field2) > 5 are binary expressions.
Case
CASE expressions return conditional values, depending on the evaluation of sub-expressions present in each of the
CASE’s branches. This expression is LSQL version of what other languages call a switch-statement or
if-elseif-else construct.
CASE
WHEN field3 = 'Robert' THEN 'Its bobby'
WHEN field3 = 'William' THEN 'Its willy'
ELSE 'Unknown'
END AS who_is_it
LSQL Streaming and Kafka Streams
LSQL engine Stream modes is built on top of Kafka Streams, and it enriches this tool with an implementation of Lenses SQL that fits well with the architecture and design of Kafka Streams.
What this means in practice is that an SQL Processor, when executed, will run a Kafka Streams instance, and it is going to be this instance that communicates with Kafka, via consumer group semantics.
Each SQL Processor has an application id which uniquely identifies it within Lenses. The application id is used as the Kafka Streams application id which in turn becomes the underlying Kafka Consumer(s) group identifier.
Scaling up or down the number of runners automatically adapts and rebalances the underlying Kafka Streams application inline with the Kafka group semantics.
The advantages of using Kafka Streams as the underlying technology for SQL Processors are several:
- Kafka Streams is a enterprise-ready, widely adopted and understood technology that integrates natively with Kafka
- Using consumer group semantics allows leveraging Kafka’s distribution of workload, fault tolerance and replication out of the box
Data as a flow of events: Streams
A stream is probably the most fundamental abstraction that LSQL Streaming provides, and it represents an unbounded sequence of independent events over a continuously changing dataset.
Let’s clarify the key terms in the above definition:
- event: an event, as explained earlier, is a datum, that is a (key, value) pair. In Kafka, it is a record.
- continuously changing dataset: the dataset is the totality of all data described by every event received so far. As such, it is changed every time a new event is received.
- unbounded: this means that the number of events changing the dataset is unknown and it could even be infinite
- independent: events don’t relate to each other and, in a stream, they are to be considered in isolation
The above should make it clear that a stream is a fitting abstraction for a Kafka topic, as they both share the above points.
The main implication of this is that stream transformations (e.g. operations that preserve the stream semantics) are stateless, because the only thing they need to take into account is the single event being transformed. Most Projections fall within this category.
Stream Example
To illustrate the meaning of the above definition, imagine that the following two events are received by a stream:
("key1", 10)
("key1", 20)
Now, if the desired operation on this stream was to sum the values of all events with the same key
(this is called an
Aggregation
), the result for "key1" would be 30, because each event is taken in isolation.
Finally, compare this behaviour with that of tables, as explained below , to get an intuition of how these two abstractions are related but different.
Stream syntax
LSQL streaming supports reading a data source (e.g. a Kafka topic) into a stream by using SELECT STREAM.
SELECT STREAM *
FROM input-topic;
The above example will create a stream that will emit an event for each and every record on input-topic, including
future ones. See more details about
SQL projection and the specific * syntax.
Data as snapshot of the state the world: Tables
While a stream is useful to have visibility to every change in a dataset, sometimes it is necessary to hold a snapshot of the most current state of the dataset at any given time.
This is a familiar use-case for a database and the Streaming abstraction for this is aptly called table.
For each key, a table holds the latest version received of its value, which means that upon receiving events for keys that already have an associated value, such values will be overridden.
A table is sometimes referred to as a changelog stream, to highlight the fact that each event in the stream is interpreted as an update.
Given its nature, a table is intrinsically a stateful construct, because it needs to keep track of what it has already been seen. The main implication of this is that table transformations will consequently also be stateful, which in this context it means that they will require local storage and data being copied.
Additionally, tables support delete semantics. An input event with a given key and a null value will be interpreted as a signal to delete the (key, value) pair from the table.
Finally, a table needs the key for all the input events to not be null.
To avoid issues, tables will ignore and discard input events that have a null key.
Table example
To illustrate the meaning of the above definition, imagine that the following two events are received by a table:
("key1", 10)
("key1", 20)
Now, if the desired operation on this table was to sum the values of all events with the same key (this is called an
Aggregation
), the result for key1 would be 20, because (key1, 20) is interpreted as an update.
Finally, compare this behaviour with that of streams, as explained above , to get an intuition of how these two abstractions are related but different.
Table syntax
LSQL Streaming supports reading a data source (e.g. a Kafka topic) into a table by using SELECT TABLE.
SELECT TABLE *
FROM input-topic;
The above example will create a table that will treat each event on input-topic, including future ones, as updates.
See
wildcard projections for more details about specific * syntax.
Tables and compacted topics
Given the semantics of tables, and the mechanics of how Kafka stores data, the LSQL Streaming will set the cleanup.policy setting of every new topic that is created from a table to compact, unless explicitly specified otherwise.
What this means is that the data on the topic will be stored with a semantic more closely aligned to that of a table
(in fact, tables in Kafka Streams use compacted topics internally). For further information regarding the implications of this, it is advisable to read the official Kafka Documentation about cleanup.policy.
Duality between streams and tables
Streams and tables have significantly different semantics and use-cases, but one interesting observation is that are strongly related nonetheless.
This relationship is known as stream-table duality. It is described by the fact that every stream can be interpreted as a table, and similarly a table can be interpreted as a stream.
- Stream as Table: A stream can be seen as the changelog of a table. Each event in the stream represents a state change in the table. As such, a table can always be reconstructed by replaying all events of a stream, in order.
- Table as Stream: A table can be seen as a snapshot, at a point in time, of the latest value received for each key in a stream. As such, a stream can always be reconstructed by iterating over each (Key, Value) pair and emitting it as an event.
To clarify the above duality, let’s use a chess game as an example.
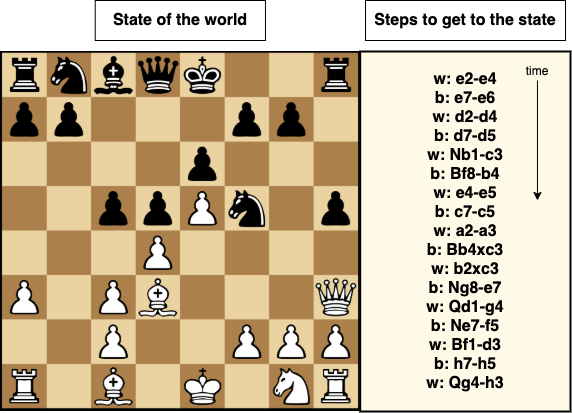
On the left hand-side of the above image a chessboard at a specific point in time during a game is shown. This can be seen as a table where the key is a given piece and the value is its position. Also, on the right hand-side there is the list of moves that culminated in the positioning described on the left; it should be obvious that this is can be seen as a stream of events.
The idea formalised by the stream-table duality is that, as it should be clear from the above picture, we can always build a table from a stream (by applying all moves in order).
It is also always possible to build a stream from a table. In the case of the chess example, a stream could be made where each element represents the current state of a single piece (e.g. w: Q h3).
This duality is very important because it is actively used by Kafka (as well as several other storage technologies), for example, to replicate data and data-stores and to guarantee fault tolerance. It is also used to translate table and stream nodes within different parts of a query.
LSQL Streaming and schemas: a proactive approach
One of the main goals of LSQL Streaming mode is to ensure that it uses all the information available to it when a SQL Processor is created to catch problems, suggest improvements and prevent errors. It’s more efficient and less frustrating to have an issue coming up during registration rather than at some unpredictable moment in the future, at runtime, possibly generating corrupted data.
SQL engine will actively check the following during registration of a processor:
- Validation of all user inputs
- Query lexical correctness
- Query semantics correctness
- Existence of the input topics used within the query
- User permissions in relation to all input and output topics
- Schema alignment between fields and topics used within the query
- Format alignment between data written and output topics, if the latter already exist
When all the above checks pass, the Engine will:
- Generate a SQL Processor able to execute the user’s query
- Generate and save valid schemas for all output topics to be created
- Monitor the processor and make such metrics available to Lenses
The Engine takes a principled and opinionated approach to schemas and typing information; what this means is that, for example, where there is no schema information for a given topic, that topic’s fields will not be available to the Engine, even if they are present in the data; also, if a field in a topic is a string, it will not be possible to use it as a number for example, without explicitly CASTing it.
The Engine’s approach allows it to support is naming and reusing parts of a query multiple times. This can be achieved using the dedicated statement WITH.
SET defaults.topic.autocreate=true;
SET commit.interval.ms='1000';
SET enable.auto.commit=false;
SET auto.offset.reset='earliest';
WITH countriesStream AS (
SELECT STREAM *
FROM countries
);
WITH merchantsStream AS (
SELECT STREAM *
FROM merchants
);
WITH merchantsWithCountryInfoStream AS (
SELECT STREAM
m._key AS l_key
, CONCAT(surname, ', ', name) AS fullname
, address.country
, language
, platform
FROM merchantsStream AS m
JOIN countriesStream AS c
ON m.address.country = c._key
WITHIN 1h
);
WITH merchantsCorrectKey AS(
SELECT STREAM
l_key AS _key
, fullname
, country
, language
, platform
FROM merchantsWithCountryInfoStream
);
INSERT INTO currentMerchants
SELECT STREAM *
FROM merchantsCorrectKey;
INSERT INTO merchantsPerPlatform
SELECT TABLE
COUNT(*) AS merchants
FROM merchantsCorrectKey
GROUP BY platform;
The WITHs allow for whole sections of the query to be reused and manipulated independently by successive statements, and all this is done maintaining schema and format alignment and correctness.
The reason why this is useful is that it allows to specify queries that split their processing flow without having to redefine parts of the topology. This, in turn, means that less data needs to be read and written to Kafka, improving performances.
This is just an example of what the LSQL Engine Streaming can offer because of the design choices taken and strict rules implemented at query registration.