4.1
Time and windows
A data stream is a sequence of events ordered by time. Each entry contains a timestamp component, which aligns it on the time axis.
Kafka provides the source for the data streams, and the Kafka message come with the timestamp built in. This is used by the Push Engines by default. One thing to consider is that from a time perspective, the stream records can be out-of-order. Two Kafka records, R1 and R2 do not necessarily respect the rule: R1 timestamp smaller than R2 timestamp.
Timestamps are required to perform time-dependent operations for streams - like aggregations and joins.
Timestamp semantics
A record timestamp value can have three distinct meanings. Kafka allows to configure a topic timestamp meaning via this the log.message.timestamp.type setting. The two supported values are CreateTime and LogAppendTime.
Event time
When a record is created at source the producer is responsible for setting the timestamp for it. Kafka producer provides this automatically and this is aligned with the CreateTime configuration mentioned earlier.
Ingestion time
At times, the data source timestamp is not available. When setting the topic timestamp type to LogAppendTime, the Kafka broker will attach the timestamp at the moment it writes it to the topic.
Processing time
The timestamp will be set to the time the record was read by the engine, ignoring any previously set timestamps.
Control the timestamp
Sometimes, when the data source is not under direct control, it might be that the record’s timestamp is actually embedded in the payload, either in the key or the value.
LSQL Streaming allows to specify where to extract the timestamp from the record by using EVENTTIME BY.
...
SELECT STREAM ...
FROM input-topic
EVENTTIME BY <selection>
...
where <selection> is a valid
selection
.
Here are a few examples on how to use the syntax to use the timestamp from the record value facet:
SELECT STREAM *
FROM <source>
EVENTTIME BY startedAt;
...
// this is identical with the above; _value qualifies to the record Value component
SELECT STREAM *
FROM <source>
EVENTTIME BY _value.startedAt;
...
// `details` here is a structure and `startedAt` a nested field
SELECT STREAM *
FROM <source>
EVENTTIME BY details.startedAt;
...
For those scenarios when the timestamp value lives within the record key, the syntax is similar:
SELECT STREAM *
FROM <source>
EVENTTIME BY _key.startedAt;
...
// `details` here is a structure and `startedAt` a nested field
SELECT STREAM *
FROM <source>
EVENTTIME BY _key.details.startedAt;
...
Output timestamp
All records produced by the LSQL Streaming will have a timestamp set and its value will be one of the following:
- For direct transformations, where the output record is a straightforward transformation of the input, the input record timestamp will be used.
- For aggregations, the timestamp of the latest input record being aggregated will be used.
- In all other scenarios, the timestamp at which the output record is generated will be used.
Time windows
Some stream processing operations, like joins or aggregations, require distinct time boundaries which are called windows. For each time window there is a start and an end, and as a result a duration. Performing aggregations over a time window, means only the records which fall within the time window boundaries are aggregated together. It might happen for the records to be out-of-order and arrive after the window end has passed, but they will be associated with the correct window.
Types
There are three time windows to be used at the moment: hopping, tumbling and session.
Duration types
When defining a time window size, the following types are available:
| Duration | Description | Example |
|---|---|---|
| ms | time in milliseconds. | 100ms |
| s | time in seconds. | 10s |
| m | time in minutes. | 10m |
| h | time in hours. | 10h |
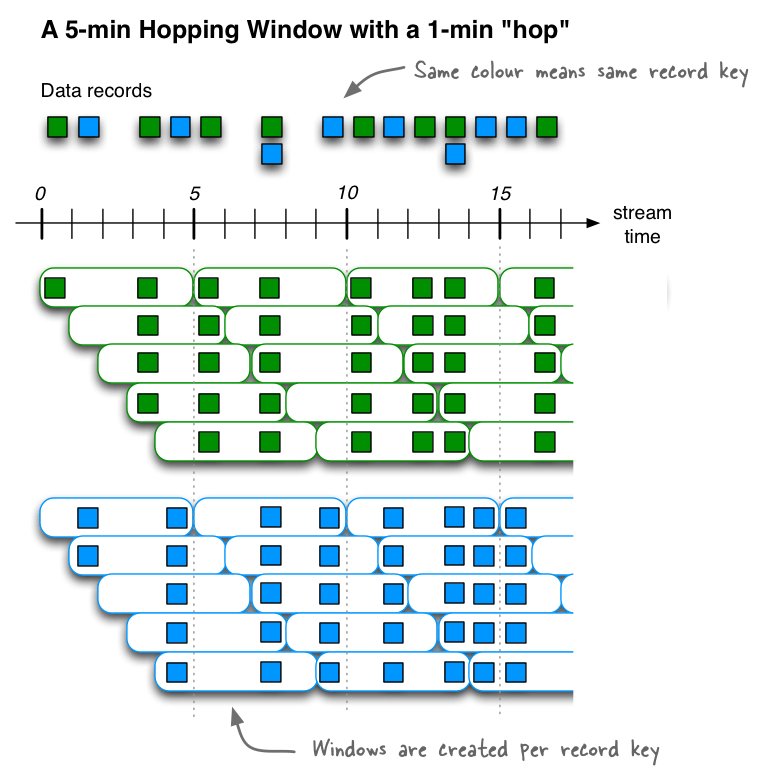
Hopping window
These are fixed size and overlapping windows. They are characterised by duration and the hop interval. The hop interval specifies how far a window moves forward in time relative to the previous window.
Since the windows can overlap, a record can be associated with more than one window.
Use this syntax to define a hopping window:
WINDOW BY HOP <duration_time>,<hop_interval>
INSERT INTO <target>
SELECT STREAM
country
, COUNT(*) AS occurrences
, MAXK_UNIQUE(points,3) AS maxpoints
, AVG(points) AS avgpoints
FROM <source>
EVENTTIME BY startedAt
WINDOW BY HOP 5m,1m
GROUP BY country
;
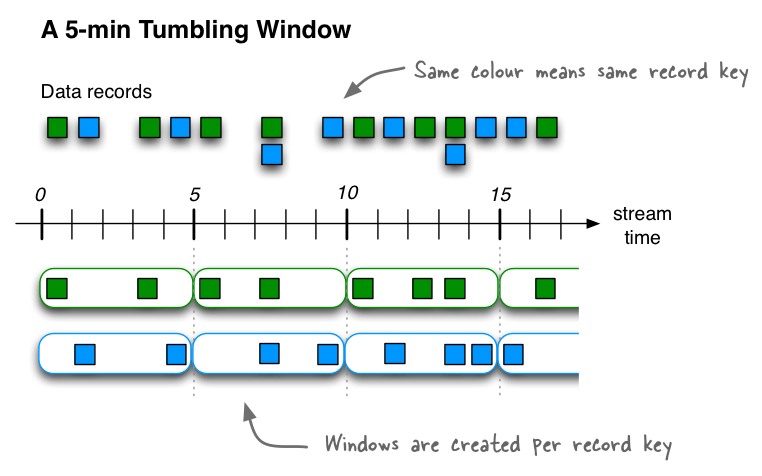
Tumbling window
They are a particularisation of hopping windows, where the duration and hop interval are equal. This means that two windows can never overlap, therefore a record can only be associated with one window.
WINDOW BY TUMBLE <duration_time>
Duration time takes the same unit types as described earlier for hopping windows.
INSERT INTO <target>
SELECT STREAM
country
, COUNT(*) AS occurrences
, MAXK_UNIQUE(points,3) AS maxpoints
, AVG(points) AS avgpoints
FROM <source>
EVENTTIME BY startedAt
WINDOW BY TUMBLE 5m
GROUP BY country
;
Session window
Unlike the other two window types, this window size is dynamic and driven by the data. Similar to tumbling window, these are non-overlapping windows.
A session window is defined by a period of activity separated by a specified gap of inactivity. Any records with timestamps that occur within the boundaries of the inactivity interval are considered part of the existing sessions. When a record arrives and its timestamp is outside of the session gap, a new session window is created and the record will belong to that.
A new session window starts if the last record that arrived is further back in time than the specified inactivity gap. Additionally, different session windows might be merged into a single one if an event is received that falls in between two existing windows, and the resulting windows would then overlap.
To define a session window the following syntax should be used:
WINDOW BY SESSION <inactivity_interval>
The inactivity interval can take the time unit type seen earlier for hopping window.
INSERT INTO <target>
SELECT STREAM
country
, COUNT(*) AS occurrences
FROM $source
WINDOW BY SESSION 1m
GROUP BY country
Session windows are tracked on per key basis. This means windows for different keys will likely have different duration. Even for the same key, the window duration can vary.
User behaviour analysis is an example of when to use session windows. They allow metrics like counting user visits, customer conversion funnel or event flows.
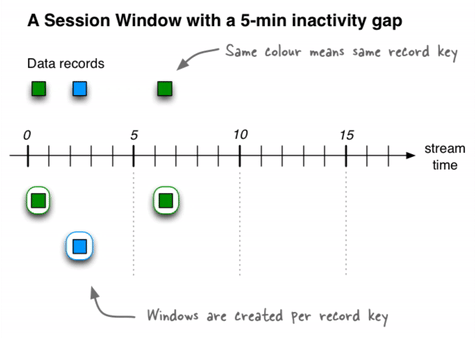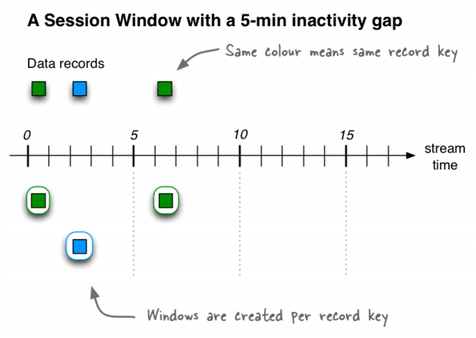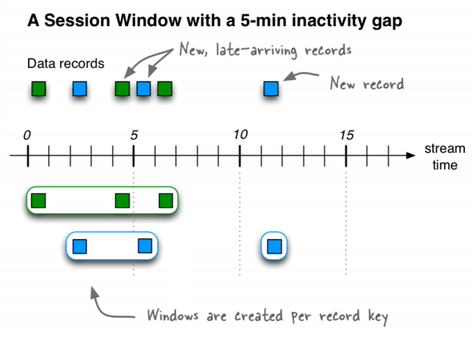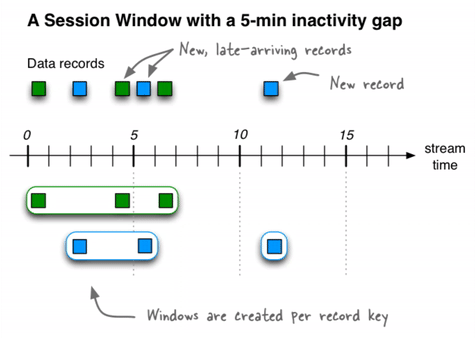
Late arrival
It is quite common to see records belonging to one window arriving late, that is after the window end time has passed. To accept these records the notion of grace period is supported. This means that if a record timestamp falls within a window W and it arrived within W + G (where G is the grace interval) then the record will be processed and the aggregations or joins will update. If, however, the record comes after the grace period then it is discarded.
To control the grace interval use this syntax:
...
WINDOW BY HOP 1m,5m GRACE BY 2h
...
WINDOW BY TUMBLE 5m GRACE BY 2h
...
WINDOW BY SESSION 1m, GRACE BY 2h
Default grace period is 24h. Until the grace period elapses, the window is not actually closed.